









یادگیری عمیق برای داده های بزرگ IoT و تجزیه و تحلیل جریان: یک بررسی کلی
چکیده — در عصر اینترنت اشیاء (IoT) ، تعدادی غیرعادی از دستگاههای سنجش برای طیف گستردهای از زمینهها و برنامهها، دادههای حسی مختلفی را در طول زمان جمعآوری و یا تولید میکنند.
بر اساس ماهیت برنامه، این دستگاهها منجر به جریان یافتن سریع دادههای بزرگ در زمان واقعی میشوند. استفاده از تجزیه و تحلیل از طریق جریان این دادهها برای کشف اطلاعات جدید، پیش بینی نگرشهای آینده و تصمیمگیریهای کنترلی، یک فرایند مهم است که IoT را تبدیل به یک الگوی شایسته برای مشاغل و یک فناوری بهبود کیفیت زندگی میکند. در این مقاله، ما یک مرور کلی راجع به استفاده از یک کلاس از تکنیکهای پیشرفته یادگیری ماشین، یعنی Deep Learning (DL)، برای تسهیل در تجزیه و تحلیل و یادگیری در حوزه IoT ارائه میدهیم. ما با بیان خصوصیات داده IoT و شناسایی دو روش اصلی برای اینگونه دادهها از دیدگاه یادگیری ماشین، یعنی تجزیه و تحلیل دادههای بزرگ IoT و دادههای جاری آن شروع میکنیم. ما همچنین درمورد اینکه چرا DL یک روش امیدوار کننده برای دستیابی به تجزیه و تحلیل مورد نظر در این نوع دادهها و برنامههای کاربردی است، بحث خواهیم کرد. سپس پتانسیل استفاده از تکنیکهای DL در حال ظهور برای تجزیه و تحلیل دادههای IoT مورد بحث قرار گرفته و قراردادها و چالشهای آن معرفی میشود. ما یک پیشزمینه جامع درمورد معماری و الگوریتمهای مختلف DL ارائه میدهیم. ما همچنین تلاشهای پژوهشی عمدهای را که از DL گزارش شدهاند در حوزه IoT تجزیه و تحلیل میکنیم. دستگاههای هوشمند IoT که DL را در پس زمینه اطلاعاتی خود گنجاندهاند نیز مورد بحث قرار گرفته است. رویکردهای اجرای DL در مراکز فضای ابری نیز در راستای حمایت از برنامههای IoT مورد بررسی قرار گرفته است. سرانجام، ما برخی از چالشها و جهتهای بالقوه را برای تحقیقات آینده روشن ساختیم. در پایان هر بخش، بر اساس آزمایشات خود و مرور ادبیات اخیر، درسهای آموخته شده را مشخص میکنیم.
کلمات کلیدی: یادگیری عمیق ، شبکه عصبی عمیق ، اینترنت اشیا ، هوش سرخود دستگاه ، داده بزرگ IoT ، تجزیه و تحلیل سریع دادهها ، تجزیه و تحلیل مبتنی بر فضای ابری.
مقدمه
چشم انداز اینترنت اشیا (IoT) ، برای تبدیل اشیا مرسوم به اشیا هوشمند با بهره گیری از طیف گسترده ای از فناوری های پیشرفته، از دستگاه های تعبیه شده و فناوری های ارتباطی گرفته تا پروتکل های اینترنتی، تجزیه و تحلیل داده ها و موارد دیگر است.
انتظار می رود که تأثیر اقتصادی بالقوه IoT فرصت های شغلی بسیاری را ایجاد کرده و رشد اقتصادی خدمات مبتنی بر IoT را تسریع کند. براساس گزارش مکنزی، تأثیر اقتصادی سالانه IoT در سال 2025 در بازه 2.7 تا 6.2 تریلیون دلار خواهد بود. بخش بهداشت و درمان با حدود 41 درصد و پس از آن صنعت و انرژی به ترتیب با 33 و 7 درصد در بازار IoT دخیل هستند. حوزه های دیگر مانند حمل و نقل، کشاورزی، زیرساخت های شهری، امنیت و خرده فروشی تقریبا 15 درصد از بازار IoT را به خود اختصاص داده اند. این انتظارات بر رشد شگرف و شیب دار خدمات IoT، داده های تولید شده آنها و به تبع آن، بازار فروش مرتبط با آنها در سال های آینده دلالت دارد.
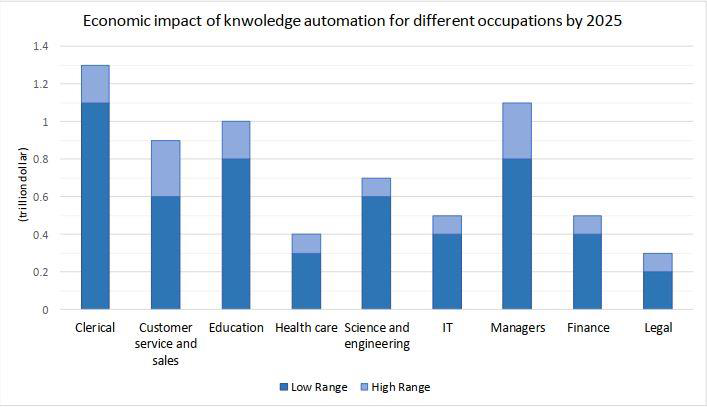
در حقیقت، یادگیری ماشینی (Machine Learning) تأثیرات خود را در شغل ها و نیروی کار خواهد داشت، زیرا بخش هایی از بسیاری از مشاغل ممکن است “برای برنامه های کاربردی ML” مناسب باشند. این امر منجر به افزایش تقاضا برای برخی محصولات ML و تقاضای حاصل از وظایف، سیستم عامل ها و متخصصان مورد نیاز برای تولید چنین محصولاتی خواهد شد. تأثیر اقتصادی یادگیری ماشینی در گزارش مکنزی تحت اتوماسیون کار دانش تعریف شده است؛ “استفاده از رایانه برای انجام کارهایی که به تجزیه و تحلیل های پیچیده، قضاوت های ظریف و حل مسئله خلاقانه متکی هستند”. در این گزارش آمده است که پیشرفت در تکنیک های ML، مانند یادگیری عمیق و شبکه های عصبی، اصلی ترین عامل اتوماسیون کار دانش است. رابط کاربری طبیعی مانند گفتار و تشخیص حرکات، دیگر امکاناتی هستند که از فناوری های ML بسیار بهرمند هستند. تأثیر احتمالی اقتصادی اتوماسیون کار دانش میتواند تا سال 2025 از 5.2 به 6.7 تریلیون دلار در سال برسد. شکل زیر نشان دهنده تجزیه این برآورد در مشاغل مختلف است. در مقایسه با تأثیر اقتصادی IoT، این برآورد بیشتر بر استخراج ارزش داده ها و تأثیرات احتمالی ML در وضعیت اقتصادی افراد و جوامع تأکید میکند. این تأثیرات اقتصادی عواقب جدی برای افراد و کشورها دارد، زیرا مردم برای حفظ سطح زندگی مطلوب خود باید با وسایل جدید کسب درآمد مناسب برای خودشان سازگار شوند.
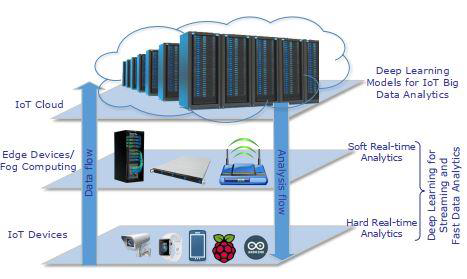
در سال های اخیر، بسیاری از برنامه های IoT در حوزه های مختلف عمودی، یعنی بهداشت، حمل و نقل، خانه هوشمند، شهرهوشمند، کشاورزی، آموزش و… پدید آمدند. عنصر اصلی اکثر این برنامه ها یک مکانیسم یادگیری هوشمند برای پیشبینی (یعنی رگرسیون، طبقه بندی و خوشه بندی)، داده کاوی و شناخت الگو یا به طور کلی تجزیه و تحلیل داده ها است. در میان بسیاری از رویکردهای یادگیری 4 ماشین، Deep Learning (DL) در سال های اخیر بطور جدی در بسیاری از برنامه های IoT مورد استفاده قرار گرفته است. این دو فناوری (یعنی DL و IoT) جزو سه روند برتر استراتژیک فناوری برای سال 2017 هستند که در Gartner Symposium / ITxpo 2016 اعلام شدند. علت این تبلیغات گسترده برای DL به این واقعیت اشاره دارد که رویکردهای سنتی یادگیری ماشین، نیازهای تحلیلی نوظهور سیستم های IoT را برطرف نمی کند. در عوض، مطابق با سلسله مراتب تولید و مدیریت داده IoT، همانگونه که در شکل 1 نشان داده شده، نیاز به رویکردهای تحلیلی مدرن مختلف و روش های هوش مصنوعی (AI) دارند.
علاقه فزاینده به اینترنت اشیا (IoT) و داده های بزرگ مشتق از آن نیاز به ذینفعان دارد تا تعریف، موانع سازندگی، پتانسیل ها و چالش ها را به وضوح درک کنند. IoT و داده های بزرگ رابطه دوطرفه دارند. از یک طرف، IoT تولید کننده اصلی داده های بزرگ است و از سوی دیگر، هدف مهمی برای تجزیه و تحلیل داده های بزرگ در جهت بهبود فرایندها و خدمات می باشد. علاوه بر این، تجزیه و تحلیل داده های بزرگ IoT ثابت کرده است که می تواند ارزش هایی را برای جامعه به ارمغان بیاورد. بعنوان مثال، گزارش شده است که با شناسایی آسیب در لوله کشی ها و رفع آنها، اداره مدیریت پارک ها در میامی حدود یک میلیون دلار از قبض های آب را پس انداز کرده است.
داده های IoT با داده های بزرگ عمومی متفاوت است. برای درک بهتر الزامات مربوط به تجزیه و تحلیل داده های IoT، باید ویژگی های آنها و چگونگی تفاوتشان با داده های بزرگ عمومی را بررسی کنیم. داده های IoT ویژگی های زیر را نشان می دهد:
• داده های استریم مقیاس بزرگ: تعداد بیشماری از دستگاه های ضبط داده برای برنامه های IoT توزیع و مستقر می شوند و به طور مداوم جریان داده ها را تولید می کنند. این منجر به ایجاد حجم عظیمی از داده های مداوم می شود.
• ناهمگونی: دستگاه های مختلف کسب اطلاعات IoT ، اطلاعات مختلفی را جمع آوری می کنند که منجر به ناهمگونی داده ها می شود.
• همبستگی زمان و مکان: در اکثر برنامه های IoT، دستگاه های حسگر به یک مکان خاص متصل شده اند و به این ترتیب برای هر فقره از داده ها دارای یک مکان و تمبر-زمان هستند.
• داده های پر سر و صدا: با توجه به تعداد کم داده ها در برنامه های IoT، بسیاری از این داده ها ممکن است هنگام دستیابی و انتقال در معرض خطا و نویز باشند.
اگرچه به دست آوردن دانش و اطلاعات پنهان از داده های بزرگ نویدبخش افزایش کیفیت زندگی ماست، اما با این حال کار آسان و ساده ای هم نیست. برای چنین کار پیچیده و چالش برانگیزی که فراتر از توانایی های رویکرد استنتاجی و یادگیری سنتی باشد، به فناوری های جدید، الگوریتم ها و زیرساخت ها نیاز است. خوشبختانه پیشرفت های اخیر در هر دو روش محاسبات سریع و تکنیک های پیشرفته یادگیری ماشین، درها را برای تجزیه و تحلیل داده های بزرگ و استخراج علومی باز می کند که برای برنامه های IoT مناسب است.
فراتر از تجزیه و تحلیل داده های بزرگ، داده های IoT برای پشتیبانی از برنامه های دارای جریان پرسرعت و نیاز به اقدامات حساس به زمان (یعنی در زمان واقعی یا نزدیک به زمان واقعی)، کلاس جدید دیگری از تجزیه و تحلیل ها، یعنی تجزیه و تحلیل سریع داده و جریان را فرا میخواند. درواقع برنامه هایی از قبیل رانندگی اتوماتیک، پیش بینی آتشسوزی، وضعیت راننده وسالخوردگان (و بنابراین هوشیاری و یا وضعیت سلامتی) شناخت و پردازش سریع داده های دریافتی و اقدامات سریع برای رسیدن به هدف خود را می طلبد. محققان متعددی رویکردها و چارچوب هایی را برای تجزیه و تحلیل سریع داده های استریم ارائه داده اند که از قابلیت های زیرساخت ها و خدمات فضای ابری استفاده می کند. با این حال، برای برنامه های IoT فوقالذکر در میان دیگران، ما به تجزیه و تحلیل سریع در سیستم عامل های مقیاس کوچکتر (یعنی در لبه سیستم) یا حتی در خود دستگاه های IoT نیاز داریم. بعنوان مثال، اتومبیل های خودکار باید در مورد اقدامات رانندگی مانند خط یا تغییرسرعت تصمیم گیری سریعی انجام دهند. در واقع این نوع تصمیمات باید با تجزیه و تحلیل سریع داده های احتمالا چندجهته و چندمنبعی، از جمله سنسورهای مختلف وسیله نقلیه (به عنوان مثال، دوربین ها، رادارها، LIDAR ، سرعت سنج، سیگنال های چپ و راست و…)، ارتباطات از سایر وسایل نقلیه و عوامل راهنمایی و رانندگی (بعنوان مثال، چراغ راهنمایی، علائم راهنمایی و رانندگی) هماهنگ باشند و از آنها پشتیبانی کنند. در این حالت، انتقال داده به سرور فضای ابری برای تجزیه و تحلیل و برگشت پاسخ، منوط به تأخیر است که می تواند باعث نقض قوانین ترافیکی و یا تصادف شود. سناریوی مهم تر، شناسایی عابران پیاده توسط وسایل نقلیه از این دست می باشد. شناخت دقیق باید در زمان واقعی انجام شود تا از بروز حوادث مرگبار جلوگیری کند. این سناریوها حاکی از آن است که تجزیه و تحلیل سریع داده برای IoT در راستای حذف تأخیرهای غیرضروری و ممنوعیت ارتباط باید نزدیک یا درون منبع داده باشد.
الف) دامنه بررسی
مدل های DL بطور کلی دو پیشرفت مهم را نسبت به رویکردهای سنتی یادگیری ماشین در دو مرحله آموزش و پیش بینی به ارمغان می آورند. در وهله اول، آنها نیاز به مجموعه ویژگی های دستساز را براي استفاده در آموزش کاهش می دهند. در نتیجه، برخی از ویژگی هایی که ممکن است از نظر انسان آشکار نباشد، توسط مدل های DL به راحتی قابل استخراج است. علاوه بر این، مدل های DL دقت را بهبود میبخشند.
در این مقاله، ما طیف گسترده ای از معماری های شبکه عصبی عمیق (DNN) را مرور می کنیم و برنامه های IoT را که از الگوریتم های DL بهرهمند شدهاند مورد بررسی قرار می دهیم. در این مقاله پنج سرویس اصلی و اساسی IoT که می توانند در دامنه های مختلف عمودی فراتر از سرویس های خاص در هر دامنه مورد استفاده قرار گیرند، شناسایی شده است. همچنین درمورد ویژگی های برنامه های IoT و راهنمای تطبیق آنها با مناسب ترین مدل DL بحث خواهد شد. این نظرسنجی درمورد تلاقی دو فناوری نوظهور، یکی در شبکه های ارتباطی، یعنی IoT و دیگری در هوش مصنوعی، یعنی DL و تفصیل برنامه های بالقوه آنها و موضوعات حل نشده است. این بررسی، الگوریتم های یادگیری مرسوم ماشین را برای تجزیه و تحلیل داده های IoT پوشش نمی دهد، زیرا برخی از تلاش های دیگر که در بخش I-B ذکر شده اند، وجود دارند که چنین رویکردهایی را پوشش داده باشند. علاوه بر این، این نظرسنجی از دیدگاه ارتباطات و شبکه، به بررسی جزئیات زیرساختی IoT نمی پردازد.
دقت در این کار به طور کلی به میزان مطابقت نتیجه پیش بینی با ارزش های حقیقی زمین اشاره دارد. خوانندگان همچنین ممکن است با دقت درجه 2 یا درجه 3 در متن روبرو شوند . به طور کلی، دقت درجه N ام به در نظر گرفتن N پاسخ با بالاترین احتمال مدل پیش بینی و بررسی اینکه آیا این مجموعه شامل مقدار مورد انتظار است یا خیر، اشاره دارد. بنابراین، دقت درجه 1 به خروجی با بیشترین احتمال اشاره می کند. به همین ترتیب، دقت درجه 3 به سه پیش بینی احتمالی اشاره دارد. به عنوان مثال، اگر ما تصویر یک ببر را به مدلی که تصاویر حیوانات را تشخیص می دهد ارائه کنیم و لیست خروجی های اینگونه برگرداند: سگ: 0 : 72 ، ببر: 0 : 69 و گربه: 0 : 58 ، دقت درجه 1 جواب مجموعه ای را شامل می شود که فقط “سگ” باشد، که اشتباه است. از طرف دیگر، دقت های درجه 2 و 3 به نتیجه منجر می شود که مجموعه های خروجی حاوی “ببر” باشند، و به همین ترتیب صحیح شمرده میشوند.
ب) کار مرتبط
حتی در ادبیات بهترین دانش های ما، مقاله ای وجود ندارد که به بررسی رابطه خاص بین داده های IoT و DL و همچنین کاربردهای روش های DL در IoT اختصاص یابد. تعداد کمی از کارهای ارائه شده متداول درمورد استخراج داده ها و روش های یادگیری ماشین وجود دارد که در محیط های IoT مورد استفاده قرار گرفته باشد. اثری که توسط تسای و همکاران ارائه شده، بر رویکردهای داده کاوی IoT تمرکز کرده است. این الگوریتم های مختلف طبقه بندی، خوشه بندی، و الگوهای مکرر داده کاوی برای زیرساخت ها و خدمات IoT مورد توجه قرار گرفته است؛ اما با این حال، رویکردهای DL را که مرکز تحقیقات ماست، درنظر نگرفته است. علاوه بر این، تمرکز آنها به طور عمده روی داده کاوی آفلاین است، در حالیکه ما یادگیری و استخراج را هم برای زمان واقعی (سریع) و هم برای تجزیه و تحلیل داده های بزرگ درنظر می گیریم.
پررا و همکاران کلاس های مختلف رویکردهای یادگیری ماشینی (نظارت شده و نظارت نشده، قوانین، منطق فازی وغیره) را در مرحله استدلال از یک سیستم محاسبات متناوب بررسی کرده و پتانسیل های استفاده از این روش ها را در سیستم های IoT مورد بحث قرار داده اند. با این وجود، آنها بازهم نقش DL را در استدلال متن مطالعه نکردند.
الشیخ و همکاران، بررسی روش های یادگیری ماشین برای شبکه های حسگر بیسیم (WSN) را ارائه می دهد. در اینجا، نویسندگان روش های یادگیری ماشینی را در جنبه های عملکردی WSN، مانند مسیریابی، بومی سازی و خوشه بندی و همچنین الزامات غیرکاربردی مانند امنیت و کیفیت خدمات را مورد مطالعه قرار دادند. آنها چندین الگوریتم را در رویکردهای نظارت شده، بدون نظارت و تقویت یادگیری بررسی کردند. این کار به زیرساختهای WSN (که یکی از زیرساخت های بالقوه برای اجرای برنامه های IoT است) متمرکز است، در حالی که کار ما به دیتابیس ها (یعنی زیرساخت های IoT) وابسته نیست و طیف گستردهای از برنامه ها و خدمات IoT را دربر می گیرد. علاوه بر این، تمرکز ما بر روی روش های مرسوم یادگیری ماشین بود، در حالی که این مقاله بر تکنیک های پیشرفته و DL متمرکز است.
سرانجام، فضل الله و همكاران به رویکردهای DL در سیستم های شبکه کنترل ترافیک پرداختند. درحالی که این کار در درجه اول بر زیرساخت های شبکه متمرکز است، با کار ما که بر استفاده از DL در برنامه های IoT متمرکز است تفاوت دارد.
فراتر از آثار خاص در مورد IoT ، کیو و همکاران چندین تکنیک یادگیری سنتی ماشین را به همراه چندین تکنیک پیشرفته از جمله DL برای پردازش داده های بزرگ عمومی بررسی کردند. به طور خاص، آنها ارتباط تکنیک های مختلف یادگیری ماشین را با فناوری پردازش سیگنال، برای پردازش و تحلیل به موقع برنامه های کاربردی داده های بزرگ برجسته کردند.
ج) مشارکت ها
این مقاله برای محققان و توسعه دهندگان IoT در نظر گرفته شده است؛ کسانی که می خواهند با استفاده از رویکردهای نوین یادگیری ماشین DL، تجزیه و تحلیل و سیستم های هوش مصنوعی، راه حل های یادگیری را روی زیرساخت های IoT خود بسازند. سهم این مقاله در این کار به شرح زیر خلاصه می شود:
• به منظور اتخاذ رویکردهای DL در اکوسیستم های IoT، ویژگی ها و مشکلات اصلی داده های IoT را شناسایی می کنیم .
• در مقایسه با برخی از کارهای مرتبط در ادبیاتی که به یادگیری ماشین در زمینه IoT پرداخته اند، ما روش های DL و کاربرد آن در حوزه IoT را برای داده های بزرگ و تجزیه و تحلیل داده های استریم بررسی می کنیم .
• ما طیف گستردهای از برنامه های IoT را که از DL در متن خود استفاده کرده اند، مرور می کنیم؛ همچنین یک مقایسه و یک راهنما برای استفاده از انواع مختلف DNN در حوزه ها و برنامه های مختلف IoT ارائه می دهیم .
• ما رویکردها و فناوری های اخیر را برای استقرار DL در کلیه سطوح سلسله مراتب IoT از دستگاه های محدود شده تا منابع فضای ابری بررسی می کنیم .
• ما برای ادغام موفقیتآمیز و بارور برنامه های DL و IoT، چالش ها و مسیرهای تحقیق را در آینده برجسته می کنیم.
بقیه این مقاله بدین شرح برگزار می شود. در بخش 2، ویژگی های داده IoT را برجسته می کنیم و توصیف می کنیم که چطور داده های بزرگ IoT و همچنین داده های سریع استریم با داده های بزرگ عمومی تفاوت دارند. بخش 3 چندین معماری معمول و موفق DNN را ارائه می دهد. این برنامه همچنین شامل شرح مختصری از پیشرفت ها با رویکرد معماری DL در زمان واقعی و همچنین الگوریتم های پیشرفته معماری است که با DL مشترک هستند. یک بررسی اجمالی نیز از چندین چارچوب و ابزار با قابلیت ها و الگوریتم های مختلفی که از DNN ها پشتیبانی می کنند ارائه شده است. برنامه های IoT در حوزه های مختلف (به عنوان مثال مراقبت های بهداشتی، کشاورزی، ITS ، و غیره) که از DL استفاده کرده اند در بخش 4 بررسی خواهد شد.
بخش 5 تلاش برای آوردن DNN به دستگاه های دارای محدودیت منابع را بررسی می کند. بخش 6 کارهایی را که بر روی بارگذاری DNN در مقیاس محاسباتی فضای ابری انجام شده اند بررسی می کند. ابعاد تحقیقات آینده و چالش های حل نشده در بخش 7 ارائه شده است. این مقاله در بخش 8 با گرفتن خلاصه ای از پیام های اصلی آن پایان یافته است. شکل 3 ساختار مقاله را نشان می دهد.
مشخصات و نیازهای داده های IOT برای تجزیه و تحلیل داده های IoT می توانند به صورت مستمر پخش شوند یا به عنوان دیتابیس های بزرگ انباشته شوند. دادههای استریم به داده های تولید شده یا ضبط شده در فواصل زمانی ناچیز از زمان اشاره دارند و برای استخراج بینش های فوری و یا تصمیمگیری سریع باید فورا مورد تجزیه و تحلیل قرار گیرند.
داده های بزرگ به مجموعه داده های عظیمی اطلاق می شود که رایانه های متداول سخت افزاری و نرمافزاری قادر به ذخیره، مدیریت، پردازش و تجزیه و تحلیل آنها نیستند. با این دو رویکرد باید به شکل متفاوتی برخورد شود زیرا الزامات آنها برای پاسخ تحلیلی یکسان نیست. نتایج حاصل از تجزیه و تحلیل داده های بزرگ میتواند پس از چند روز تولید داده تحویل داده شود، اما تجزیه و تحلیل داده های استریم باید در دامنه چند صدم میلی ثانیه تا چند ثانیه آماده تحویل باشند.
ادغام داده ها و به اشتراک گذاری آنها نقش مهمی را در توسعه محیط های همه جانبه بر اساس داده های IoT ایفا می کند. این نقش برای برنامه های IoT حساس به زمان ضروری است زیرا در آن به همجوشی به موقع داده ها نیاز است تا همه قطعات داده ها را برای تجزیه و تحلیل و درنتیجه ارائه بینش عملی قابل اعتماد و دقیق بدست بدهند. علم و همكاران یک مقاله پیمایشی ارائه دادند که در آن تکنیک های تلفیق داده ها برای محیط های IoT مورد بررسی قرار می گیرد و بدنبال آن چندین فرصت و چالش هم وجود دارد.
الف) دادههای سریع و استریم IoT
بسیاری از تلاش های تحقیقاتی، تجزیه و تحلیل داده های استریم را ارائه می دهند که میتوانند بطور عمده در سیستم های محاسباتی با کارایی بالا یا سیستم عامل های فضای ابری مستقر شوند. تجزیه و تحلیل داده های استریم در چنین چارچوب هایی بر اساس موازی سازی داده ها و پردازش افزایشی است. با موازی سازی داده ها، یک مجموعه داده بزرگ به چندین مجموعه داده کوچکتر تقسیم می شود ، که در انها تجزیه و تحلیل های موازی به طور همزمان انجام میگیرد. پردازش افزایشی به واکشی دسته ای کوچک از داده ها گفته می شود که باید به سرعت در خط لول های از کارهای محاسباتی پردازش شوند.
اگرچه این تکنیک ها برای بازگشت پاسخی از چارچوب تحلیلی داده های استریم، تأخیر را در زمان کاهش می دهند، اما بهترین راه حل ممکن برای حفظ دقت زمانی برنامه های IoT نیستند. با نزدیک کردن تجزیه و تحلیل داده های استریم به دیتابیس (یعنی دستگاه های IoT یا دستگاههای لبه)، نیاز به موازیسازی حساس داده ها و پردازش افزایشی بیشتراست زیرا اندازه داده های موجود درمنبع امکان پردازش سریع آن را فراهم می کند. با اینحال، استفاده از آنالیز سریع در دستگاه های IoT چالش های خاص خود را از قبیل محدود کردن محاسبات، ذخیره سازی و منابع قدرت را در دیتابیس ها به همراه دارد.
ب) داده های بزرگ IoT
IoT بعنوان یکی از منابع اصلی داده های بزرگ شناخته شده است، زیرا مبتنی بر اتصال تعداد زیادی از دستگاه های هوشمند به اینترنت است تا وضعیتی را که مرتبا از محیط اطراف خود ضبط کرده اند گزارش کنند. شناخت و استخراج الگوهای معنی دار از داده های ورودی خام عظیم، ابزار اصلی تجزیه و تحلیل داده های بزرگ است، زیرا نتیجه آن در سطوح بالاتر بینش برای تصمیمگیری و پیشبینی مشخص خواهد شد. بنابراین، استخراج این بینش ها و دانش از داده های بزرگ برای بسیاری از مشاغل از اهمیت بالایی برخوردار است، زیرا این امکان را به آنها می دهد تا مزیتهای رقابتی کسب کنند. در علوم اجتماعی، هیلبرت به ترتیب تأثیر تحلیل داده های بزرگ را با اختراع تلسکوپ و میکروسکوپ روی نجوم و زیست شناسی مقایسه می کند.
گوگل ترند در سال های اخیر توجه بیشتری را نسبت به یادگیری عمیق نشان داده است. چندین اثر ویژگی های کلی داده های بزرگ را از جنبه های مختلف از نظر حجم، سرعت و تنوع شرح داده اند. با اینحال، ما تعریفی عمومی از داده های بزرگ را برای توصیف داده های بزرگ IoT از طریق ویژگی های ” V6 ” زیر انجام می دهیم:
• حجم: حجم داده ها عاملی تعیین کننده برای در نظر گرفتن یک مجموعه داده به عنوان داده های بزرگ یا داده های عظیم و بسیار بزرگ سنتی است. مقدار داده های تولید شده با استفاده از دستگاه های IoT بسیار بیشتر از گذشته است و به وضوح با این ویژگی مطابقت دارد.
• سرعت: میزان تولید و پردازش داده های بزرگ IoT به اندازه کافی بالا هست تا بتواند از دسترسی به داده های بزرگ در زمان واقعی پشتیبانی کند. با توجه به نرخ بالای تولید داده، این موضوع نیاز ما به ابزارها و فناوری های پیشرفته را برای تجزیه و تحلیل توجیه میکند.
• تنوع: بطورکلی، داده های بزرگ به اشکال و انواع مختلفی درمی آیند. این امر ممکن است از داده های ساختاری، نیمه ساختار یافته و بدون ساختار نشات گرفته باشد. طیف گسترده ای از انواع داده ها مانند متن، صدا، فیلم، داده های حسی و غیره ممکن است توسط IoT تولید شود.
• صحت: این امر به کیفیت، قوام و میزان قابل اعتماد بودن داده ها اشاره دارد که به نوبه خود منجر به تجزیه و تحلیل دقیق می شود. این ویژگی برای نگه داشتن برنامه های IoT، به ویژه آنهایی که داده های مربوط به جمعیت را دارند، نیاز به توجه ویژه دارد.
• تنوع پذیری: این ویژگی به نرخ های مختلف جریان داده اشاره دارد. بسته به ماهیت برنامه های IoT، اجزای تولید کننده داده های مختلف ممکن است جریان داده های متناقض داشته باشند. علاوه بر این، یک منبع داده می تواند نرخ های مختلف بار داده را بر اساس زمان های خاص داشته باشد. بعنوان مثال، یک برنامه سرویس پارکینگ که از سنسورهای IoT استفاده می کند ممکن است حداکثر بار داده را در ساعت های شلوغ دارا باشد.
• ارزش: ارزش، تبدیل داده های بزرگ به اطلاعات مفید و بینش هایی است که مزیت رقابتی را
برای سازمان ها به ارمغان می آورد. ارزش داده به شدت به فرآیندهای و خدمات اساسی و نحوه برخورد با داده ها بستگی دارد. بعنوان مثال، یک برنامه خاص (مثلا نظارت بر علائم حیاتی پزشکی) ممکن است نیاز به ضبط داده های حسگر داشته باشد، درحالیکه یک سرویس پیشبینی آب وهوا فقط به نمونه های تصادفی از داده های سنسورهای آن نیاز داشته باشد. یک نمونه دیگر، ممکن است یک ارائه دهنده کارت اعتباری نیاز داشته باشد که داده ها را برای مدت زمانی مشخص نگه داشته و پس از آن، آنها را دور بیندازد.
فراتر از خواص فوق، محققان خصوصیات دیگری مانند موارد زیر را شناخته اند:
• داده های بزرگ میتوانند یک محصول جانبی یا ردپای یک فعالیت دیجیتالی در تداخل با IoT باشند. استفاده از رایج ترین اصطلاحات جستجوی گوگل برای پیشبینی آنفولانزای فصلی نمونه خوبی از چنین محصول جانبی دیجیتالی است.
• سیستم های داده بزرگ باید از نظر افقی قابل قیاس باشند، یعنی منابع داده های بزرگ باید بتوانند به چندین مجموعه داده گسترش یابند. این ویژگی همچنین منجر به پیچیدگی داده های بزرگ می شود که به نوبه خود چالش های دیگری مانند انتقال و پاکسازی داده ها را نیز تحمیل می کند. انجام تجزیه و تحلیل بیش از جریان مداوم داده، در ادبیات معمولا بعنوان پردازش استریم یا گاهی پردازش رویداد پیچیده (CEP) گفته می شود.
اشتروباخ و همکاران، یک چارچوب بزرگ تحلیلی داده IoT برای پشتیبانی از ویژگی های حجم و سرعت تحلیلی آنها پیشنهاد داده اند. ادغام داده های بزرگ IoT و تجزیه و تحلیل داده های استریم، یک موضوع حل نشده است که نیاز به تحقیقات بیشتری دارد، همچنین بعنوان بخشی از این کار مورد مطالعه قرار گرفته است. با این حال ، چارچوب پیشنهادی آنها برای استقرار در زیرساخت های فضای ابری طراحی شده است. علاوه بر این، تمرکز آنها روی جنبه مدیریت داده های دارای چارچوب است و از مدل های پیشرفته یادگیری ماشین مانند DL استفاده نمی کنند.
سایر محصولات از رده خارج مانند آپاچی استورم 3 نیز برای تجزیه و تحلیل در زمان واقعی روی فضای ابری موجود است. شکاف بزرگ این مسئله، عدم وجود چارچوب ها و الگوریتم هایی است که می تواند در مه (مثلا لبه سیستم) یا حتی در دستگاه های IoT مستقر شود. وقتی DL در چنین مواردی نقش ایفا کند، باید بین عمق و عملکرد DNN مبادل های درنظر گرفته شود.
یادگیری عمیق
DL متشکل از تکنیک های یادگیری نظارت شده یا بدون نظارت است که براساس بسیاری از لایه های شبکه عصبی مصنوعی (ANN) ساخته شده است که قادر به بازنمایی سلسله مراتبی در معماری های عمیق هستند. معماری DL از چندین لایه پردازش تشکیل شده است که هر لایه قادر به تولید پاسخ های غیرخطی بر اساس داده های لایه ورودی خودش است. عملکرد DL از مکانیسم های مغز و نورون های انسان برای پردازش سیگنال ها تقلید می کند.
معماری DL در سال های اخیر در مقایسه با سایر رویکردهای یادگیری سنتی ماشین، مورد توجه بیشتری قرار گرفته است. چنین رویکردهایی به عنوان نسخه های ساختاری معماری کم عمق (به عنوان مثال، یک زیر مجموعه محدود) از DL در نظر گرفته می شوند. شکل 4 روند جستجوی پنج الگوریتم یادگیری محبوب ماشین را در روندهای گوگل نشان می دهد که در آن DL محبوبیت بیشتری پیدا می کند.
اگرچه ANN ها در دهه های گذشته معرفی شده اند، اما روند روبه رشد DNN ها از سال 2006 شروع شد که جی. هینتون و همکاران مفهوم شبکه های عمیق-باور را ارائه دادند. پس از آن، عملکرد مدرن این فناوری در زمینه های مختلف هوش مصنوعی ازجمله شناسایی تصویر، بازیابی تصویر، موتورهای جستجو و بازیابی اطلاعات و پردازش زبان طبیعی مشاهده شده است.
تکنیکهای DL بر روی دامنه ANN های سنتی توسعه یافته اند. شبکه های عصبی بازخورد یا همان FNN ها (پیشتر، ادراک چندلایهای) در دهه های گذشته برای آموزش سیستم ها استفاده شده اند، اما وقتی تعداد لایه ها بیشتر شود، آموزش آنها دشوار می شود. نورون واحدی از شبکه های عصبی مصنوعی است، که دارای چندین ورودی، وزن و تعصب قابل آموزش می باشد.
اندازه كوچك از داده های تمریني نیز عامل دیگري بود كه منجر به ایجاد مدل های اضافي میشود. علاوه بر این، محدودیت در قابلیت های محاسباتی در آن روزها جلوی اجرای FNN های عمیق تر و کارآمدتر را گرفته بود. این محدودیت های محاسباتی اخیرا به دلیل پیشرفت های سخت افزاری به طور کلی، توسعه واحدهای پردازش گرافیکی (GPU) و شتاب دهنده های سخت افزاری به طور خاص برطرف شده است. فراتر از جنبه های ساختاری و اهمیت عمق معماری DL و همچنین پیشرفت های سخت افزاری، تکنیک های DL از پیشرفت های موجود در الگوریتم های آموزش موثر در شبکه های عمیق بهرمند شده اند:
• استفاده از واحدهای خطی اصلاح شده (ReLUs) بعنوان عملکرد فعال سازی،
• معرفی روش های رهاسازی،
• اولیه سازی تصادفی برای اوزان شبکه،
• پرداختن به تنزل دقت آموزش توسط شبکه های یادگیری باقیمانده،
• حل مشکل شیب ناپدید شده درست مثل از بین بردن مشکل شیب با معرفی و تقویت شبکه های حافظه کوتاه مدت،
یکی از مزیت های معماری DL در مقایسه با ANN های سنتی، این است که تکنیک های DL می توانند ویژگی های پنهان را از داده های خام بیاموزند. هر لایه بر اساس خروجی های لایه قبلی، مجموعه ای از ویژگی ها را آموزش می دهد. بیشترین لایه ها می توانند ویژگی های پیچیده تری را تشخیص دهند، زیرا ویژگی های لایه های قبلی را جمع می کنند و در نهایت نوترکیب می شوند که به این امر، سلسله مراتب ویژگی ها گفته می شود. بعنوان مثال، در صورت وجود مدل تشخیص چهره، داده های خام تصویر از پرتره ها بعنوان بردار پیکسل ها، به یک مدل در لایه ورودی آن تغذیه می شوند. سپس هرلایه پنهان می تواند ویژگی های انتزاعی تر از خروجی های لایه قبلی را بیاموزد؛ بعنوان مثال اولین لایه پنهان، خطوط و لبه ها را مشخص می کند، لایه دوم اجزای چهره مانند بینی، چشم ها و غیره را شناسایی می کند و لایه سوم همه موارد قبلی را ترکیب می کند تا از آن در راستای استخراج ویژگی هایی برای تولید چهره استفاده کند.
با اینحال، پیشرفت های گزارش شده از مدل های DL بر اساس ارزیابی های تجربی است، و هنوز هیچ پایه و اساس تحلیلی مشخصی برای پاسخ به این دلیل که چرا تکنیک های DL بهتر از همتایان کم عمق خود هست، وجود ندارد. علاوه بر این، هیچ مرز مشخصی بین شبکه های عمیق و کم عمق بر اساس تعداد لایه های پنهان موجود نیست. به طور کلی، شبکه های عصبی با دو یا چند لایه پنهان که الگوریتم های آموزش پیشرفته اخیر را شامل می شوند، بعنوان مدل های عمیق درنظر گرفته می شوند. همچنین، شبکه های عصبی متداوم با یک لایه پنهان بعنوان شبکه عمیق شناخته می شوند، زیرا یک چرخه در واحدهای لایه پنهان دارند که می توانند در یک شبکه عمیق معادل کنترل شوند.
الف) معماری
در این بخش، مختصرا به چند مدل رایج DL و همچنین برترین معماری هایی که در سال های اخیر معرفی شده اند می پردازیم. خوانندگان علاقمند می توانند به ادبیات دیگری که مدل ها و معماری DL را با جزئیات بیشتری بررسی کرده است مراجعه کنند. جدول I بطور خلاصه این مدل ها، ویژگی ها، خصوصیات و برخی از کاربردهای نمونه را نشان می دهد.
جدول 1 خلاصه مدل های یادگیری عمیق DNN از یک لایه ورودی، چندین لایه پنهان و یک لایه خروجی تشکیل شده است. هر لایه شامل چندین واحد به نام نورون است. یک نورون اطلاعات را از چندین ورودی دریافت می کند، یک جمع بندی وزنی بیش از ورودی های خود را انجام می دهد، سپس حاصل را از یک عملکرد فعال سازی برای تولید خروجی عبور می دهد. هر نورون، برداری از وزن های مرتبط با اندازه ورودی آن و همچنین سوگیری دارد که باید طی فرایند آموزش بهینه شود. شکل 5 ساختار یک نورون را نشان می دهد.
در فرآیند آموزش، لایه ورودی، وزنها را (معمولا به طور تصادفی) به داده های آموزشی ورودی اختصاص می دهد و آن را به لایه بعدی منتقل می کند؛ لایه بعدی نیز وزن را به ورودی خود اختصاص می دهد و خروجی آنها را تولید می کند، که به عنوان ورودی برای لایه زیرین عمل می کند. در آخرین لایه، خروجی نهایی نمایانگر پیش بینی مدل است. یک تابع محاسبه ضرر، با محاسبه میزان خطا بین مقادیر پیش بینی شده و درست، صحت این پیش بینی را تعیین می کند و یک الگوریتم بهینه سازی مانند نزول شیب تصادفی (SGD) برای تنظیم وزن نورون ها با محاسبه شیب عملکرد از دست دادن استفاده می شود. میزان خطا در سراسر شبکه در لایه ورودی پخش میشود (معروف به الگوریتم بازنشر). سپس شبکه بعد از تعادل وزن، بر روی هر نورون این چرخه تمرین را تکرار می کند تا اینکه میزان خطا در زیر آستانه مورد نظر قرار بگیرد. در این مرحله، DNN آموزش دیده و آماده استنتاج است. در شکل 6 ، مکانیسم سطح بالای آموزش برای مدل های DL نشان داده شده است.
در یک طبقه بندی گسترده، مدل های DL در سه دسته قرار می گیرند، یعنی مدل های تولیدی، تمیز دهنده و ترکیبی. اگرچه نمیتوان مرز محکمی را میان داده ها قائل شد، اما تمیز دهنده معمولا رویکردهای یادگیری نظارت شده را ارائه می دهند، در حالی که از مدل های تولیدی برای یادگیری بدون نظارت استفاده می شود. مدل های ترکیبی مزایای هردو مدل تمیز دهنده و تولیدی را شامل میشوند.
1) شبکه های عصبی مفهومی (CNN):
برای کارهای مبتنی بر بینایی، آموزش DNN با اتصال متراکم بین لایه ها دشوار است و مقیاس خوبی ندارد؛ یکی از دلایل مهم آن، خاصیت ترجمه-متغیر بودن چنین مدل هایی است. بنابراین آنها ویژگی هایی را که ممکن است در تصویر دگرگون شوند، نمی آموزند (بعنوان مثال چرخش دست در تشخیص پوز).
CNN ها با پشتیبانی از محاسبات ترجمه-معادله، این مشکل را حل کرده اند. CNN یک ورودی 2 بعدی (به عنوان مثال، یک تصویر یا سیگنال گفتاری) را دریافت می کند و ویژگی های سطح بالایی را از طریق یک سری لایه های پنهان استخراج می کند. لایه های پنهان از لایه های پیچشی و همچنین لایه های کاملا متصل در انتها تشکیل شده است. لایه حلقوی در هسته CNN واقع شده که از مجموعه ای از پارامترهای قابل یادگیری به نام فیلترها تشکیل شده است که همان شکل ورودی اما دارای ابعاد کوچکتر است. در فرایند آموزش، فیلتر هر لایه مفهومی از کل حجم ورودی عبور می کند؛ بعنوان مثال، در صورت وجود یک تصویر، از عرض و طول تصویر عبور کرده و یک محصول داخلی از ورودی و فیلتر را محاسبه می کند. این محاسبه در کل ورودی به یک نقشه ویژگی های فیلترها منتهی می شود.
یکی دیگر از ساختمان های CNN، لایه های انباشته شده است که روی نقشه های نشانگر ویژگی ها کار می کند. هدف از داشتن لایه های انباشته، کاهش فاصله مکانی پشتیبانی است، تا هم تعداد پارامترها و میزان زمان محاسبه کاهش یابد و هم احتمال پوشش بیش از حد پایین بیاید. حداکثر انباشت، یک رویکرد رایج است که فضای ورودی را به مناطق بدون همپوشانی تقسیم کرده و حداکثر مقدار را برای هر منطقه انتخاب می کند.
آخرین مؤلفه مهم در CNN ،ReLU است که از سلول های عصبی با عملکرد فعال سازی به شکل f(x) = max(0; x) تشکیل شده است. معرفی این عملکرد فعال سازی در CNN به شکلی معقول، منجر به افزایش زمان آموزش بدون تأثیرگذاری در شبکه به صورت منفی می شود. شکل 7 ساختار یک CNN را نشان می دهد.
تفاوت اصلی بین CNN ها و شبکه های کاملا متصل این است که هر نورون موجود در CNN ها تنها به یک زیر مجموعه کوچک از ورودی متصل است. این تعداد کل پارامترهای موجود در شبکه را کاهش داده و پیچیدگی زمانی فرایند آموزش را بهبود می بخشد. به این ویژگی، اتصال محلی گفته می شود.
بسیاری از دستگاههای IoT مانند هواپیماهای بدون سرنشین، تلفن های هوشمند و اتومبیل های متصل هوشمند، مجهز به دوربین هستند. معماری CNN و تغییرات آن برای انواع سناریوهای کاربردی که شامل این دستگاه ها شده، مورد بررسی قرار گرفته است. برخی از برنامه های معمولی شامل پیش بینی سیل و رانش زمین از طریق تصاویر اتوماتیک، تشخیص مسمومیت های گیاهی با استفاده از تصاویر گیاهان بر روی تلفن های هوشمند و تشخیص علائم راهنمایی و رانندگی با استفاده از دوربین های وسایل نقلیه می باشد.
2) شبکه های عصبی مکرر (RNN):
در بسیاری از کارها، پیشبینی به چندین نمونه قبلی بستگی دارد؛ به گونه ای که علاوه بر طبقه بندی نمونه های فردی، ما هم نیاز به تجزیه و تحلیل توالی ورودی ها داریم. در چنین برنامه های کاربردی، یک شبکه عصبی تغذیه پیشرو قابل استفاده نیست زیرا هیچ وابستگی را بین لایه های ورودی و خروجی به عهده نمی گیرد. RNN برای حل مسئله مشکلات پیدرپی (مثلا گفتار یا متن) یا مشکلات سری زمانی (داده های حسگر) با طول های مختلف ایجاد شده است. تشخیص رفتارهای رانندگان در وسایل نقلیه هوشمند، شناسایی الگوهای حرکتی افراد و برآورد مصرف انرژی یک خانواده، نمونه هایی از کاربرد RNN است. ورودی RNN شامل نمونه فعلی و نمونه مشاهده شده قبلی است. به عبارت دیگر ، خروجی RNN در مرحله t-1 بر خروجی در مرحله t تأثیر می گذارد. هر نورون به یک حلقه بازخورد مجهز است که خروجی فعلی را بعنوان ورودی برای مرحله بعدی باز می گرداند. این ساختار می تواند به گونه ای بیان شود که هر نورون در RNN دارای یک حافظه داخلی باشد که اطلاعات محاسبات را از ورودی قبلی حفظ می کند.
برای آموزش شبکه، از الگوریتم انتشار بازگشتی، با نام بازگشت انتشار در طول زمان (BPTT) استفاده می شود. با توجه به وجود چرخه در سلول های عصبی، ما نمیتوانیم از انتشار بازگشتی اصلی در اینجا استفاده کنیم، زیرا اینکار بر اساس مشتق خطا، با توجه به وزن در لایه بالایی آنها عمل می کند، درحالی که در RNNها مدل لایه ای پشته ای نداریم. هسته اصلی الگوریتم BPTT روشی است به نام عدم کنترل RNN، به گونه ای که ما در طول زمان با یک شبکه تغذیه کننده رو به رو می شویم. شکل 8 ساختار یک RNN و مفهوم کنترل نشده را نشان می دهد.
RNN های سنتی می توانند به عنوان مدل های عمیق درنظر گرفته شوند زیرا میتوان آنها را بعنوان چندین لایه غیرخطی نورون بین لایه ورودی و لایه خروجی در زمان کشف آنها مشاهده کرد. با اینحال، باتوجه به معماری و عملکرد RNN ها، لایه های پنهان در RNN ها قرار است به جای بازنمایی سلسله مراتبی از ویژگی ها، حافظه هایی را فراهم کنند. چندین روش برای عمیق تر ساختن RNN وجود دارد، از جمله اضافه کردن لایه های بیشتر بین لایه های ورودی و پنهان، جمع کردن لایه های پنهان تر و اضافه کردن لایه های بیشتر بین لایه های پنهان و لایه خروجی.
3) حافظه کوتاه مدت بلند (LSTM):
LSTM یک شاخه از RNN است. گونه های مختلفی از LSTM ارائه شده است، اگرچه بیشتر آنها از همان طراحی شبکه اصلی پیروی کرده اند. LSTM برای واحدهای خود از مفهوم دروازه استفاده می کند که هر یک مقدار بین 0 تا 1 را بر اساس ورودی خود محاسبه می کند. علاوه بر یک حلقه بازخورد برای ذخیره اطلاعات، هر نورون در LSTM (همچنین به آن سلول حافظه نیز گفته می شود) دارای یک دروازه فراموشی ضربدری، یک دروازه برای خواندن و یکی برای نوشتن است. این دروازه ها برای کنترل دسترسی به سلول های حافظه و جلوگیری از آشفتگی آنها توسط ورودی های بی ربط معرفی می شوند. هنگامی که دروازه فراموشی فعال است، نورون داده های خود را درون خودش مینویسد. هنگامیکه دروازه فراموشی با ارسال یک 0 خاموش می شود، نورون آخرین محتوای خود را فراموش می کند. هنگامیکه دروازه نوشتن روی 1 تنظیم شده است، سایر سلول های عصبی متصل به آن می توانند داده را روی آن نورون بنویسند. اگر دروازه خواندن روی 1 تنظیم شود، سلول های عصبی متصل می توانند محتوای نورون را بخوانند. شکل 9 این ساختار را نشان می دهد.
تفاوت مهم LSTM ها در مقایسه با RNN ها این است که واحدهای LSTM از دروازه های فراموشی استفاده می کنند تا بطور فعال حالت سلول را کنترل کنند و از عدم تخریب آنها اطمینان داشته باشند.
دروازه ها میتوانند از سیگموئید یا برنزه به عنوان عملکرد فعال سازی خود استفاده کنند. در حقیقت، این کارکردهای فعال سازی دلیل اصلی مشکل ناپدید شدن شیب در حین بازپرداخت در مرحله تمرینی سایر مدل ها هستند. با آموختن داده هایی که باید در LSTM بخاطر بیاورید، محاسبات ذخیره شده در سلول های حافظه با گذشت زمان تحریف نمی شوند. BPTT یک روش متداول برای آموزش شبکه در راستای به حداقل رساندن خطا است. شکل 9 ساختار یک سلول حافظه LSTM فلش های ممتد، جریان داده ها را نشان می دهد و فلش های نقطه چین، سیگنال هایی را از دروازه ها نشان می دهند.
هنگامی که داده ها با وابستگی طولانی به زمان مشخص می شوند، مدل های LSTM عملکرد بهتری نسبت به مدل های RNN دارند. این تاخیر طولانی وابستگی را میتوان در برنامه های IoT از قبیل شناخت فعالیت های انسانی، پیشبینی عملکردهای آموزشی در برنامه های آنلاین و پیشبینی بحران ها بر اساس نظارت زیست محیطی مشاهده کرد که تعدادی از آنها را شاهد هستیم.
4) رمزنگارهای خودکار (AE):
AE ها شامل یک لایه ورودی و یک لایه خروجی هستند که از طریق یک یا چند لایه پنهان به هم متصل می شوند. AE ها به تعداد واحدهای ورودی و خروجی یکسان هستند. این شبکه ها با هدف تبدیل مجدد ورودی به خروجی با ساده ترین روش ممکن هستند، به گونهای که ورودی را خیلی هم تحریف نکند. این نوع شبکه های عصبی عمدتا برای حل مشکلات یادگیری بدون نظارت، درست مثل یادگیری انتقال مورد استفاده قرار می گیرند. باتوجه به رفتار آنها درمورد ساخت ورودی در لایه خروجی، از AE ها عمدتا برای کارهای تشخیص خطا استفاده می شود. این مورد برای IoT صنعتی مورد توجه بسیاری از برنامه ها مانند تشخیص اشتباه در دستگاه ها و ماشین های سخت افزاری و تشخیص ناهنجاری در عملکرد خطوط مونتاژ است.
AE ها دو مؤلفه اصلی دارند: یک رمزگذار و یک رمزشکن. رمزگذار ورودی را دریافت می کند و آن را به یک بازنمایی جدید تبدیل میکند، که معمولا به آن یک کد یا متغیر پنهان گفته می شود. رمزشکن کد تولید شده را از رمزگذار دریافت می کند و آن را به یک بازسازی ورودی اصلی تبدیل میکند. روش آموزش در AE شامل به حداقل رساندن خطای بازسازی، یعنی خروجی و ورودی است که حداقل اختلاف را نشان می دهد. شکل 10 ساختار AE معمولی را نشان می دهد. چندین تغییر و الحاقی درمورد AE ها مانند AE نویزشکن، AE قراردادی، AE انباشته شده، AE پراکنده و AE متغیر وجود دارد.
5) رمزگذارهای خودکار مختلف (VAEs):
VAEs، معرفی شده در سال 2013، یک چارچوب مدل تولیدی محبوب است که فرضیات ما درمورد ساختار داده های آن قوی نیست، در حالی که داشتن یک روند آموزش سریع از طریق انتشار بازگشتی می باشد. علاوه بر این، این مدل برای یادگیری نیمه نظارت شده استفاده شده است. بنابراین، این برای راه حل های IoT یک مزیت است که با داده های متنوع و کمبود داده های دارای برچسب سروکار دارند.
چنین کاربردهایی شامل تشخیص عدم موفقیت در سنجش یا تحریک سطوح و تشخیص نفوذ در سیستم های امنیتی است. برای هر نقطه داده x، یک بردار از متغیرهای پنهان مربوطه وجود دارد که توسط z نشان داده شده است. معماری آموزش یک VAE به ترتیب از یک رمزگذار و یک رمزشکن با پارامترهای φ و θ تشکیل شده است. توزیع شکل qφ(zjx) ثابت، به رمزگذار در تخمین توزیع خلفی pθ (zjx) کمک می کند. این مدل از دو شبکه تشکیل شده است: یکی نمونه های مولد و دیگری اجراگر استنتاج تقریبی. شماتیکی از VAE در شکل 11 نشان داده شده است.
6) شبکه های مخالف مولد (GAN):
GAN ها که توسط گودفلو و همکاران معرفی شده اند، متشکل از دو شبکه عصبی هستند، یعنی شبکه های تولیدی و تمیز دهنده که برای تولید داده های مصنوعی و با کیفیت همکاری می کنند. شبکه پیشین (پیشتر تولید کننده) پس از یادگیری توزیع داده از یک مجموعه داده آموزشی، مسئولیت ایجاد داده های جدید را برعهده دارد.
لایه های قابل مشاهده و پنهان دارای جانبداری جداگانهای هستند. شبکه دوم (پیشتر تشخیص دهنده) کار تمایز میان داده های واقعی (حاصل از دادههای آموزشی) و داده های ورودی جعلی (از تولید کننده) را انجام می دهد. شبکه مولد برای تولید داده های ورودی که تشخیص دهنده را فریب می دهند بهینه شده است (یعنی داده هایی که تشخیص دهنده نمی تواند به راحتی متوجه جعلی یا واقعی بودن آنها شود). به عبارت دیگر، شبکه مولد با یک شبکه تمیز دهنده مخالف رقابت می کند. شکل 12 مفهوم GAN ها را نشان می دهد.
عملکرد هدف در GAN ها بر اساس بازی های مینیماکس است، بگونه ای که یک شبکه سعی دارد عملکرد ارزش را به حداکثر برساند و شبکه دیگر در تلاش برای به حداقل رساندن آن باشد. در هر مرحله از این بازی تخیلی، مولد مایل به گول زدن تشخیص دهنده یا تولید یک سری از داده ها با استفاده از نویزهای موجود در بازی است. از طرف دیگر، تشخیص دهنده چندین نمونه داده واقعی را از مجموعه آموزشی به همراه نمونه از مولد دریافت می کند. سپس وظیفه آن، تشخیص تمایز میان داده های واقعی و جعلی است. در نظر گرفته شده است که در صورت صحیح بودن طبقه بندی، اینگونه تمایزها عملکرد رضایت بخشی داشته باشد؛ مولد هم درصورتی که مثال هایی بزند که قادر به گول زدن تشخیص دهنده باشد، عملکرد خوبی دارد. سپس پارامترهای تشخیص دهنده و مولد بهروز می شوند تا برای دور بعدی بازی آماده گردند. خروجی تشخیص دهنده به مولد کمک میکند تا داده های تولید شده خود را برای دور بعدی بهینه کند.
در برنامه های IoT میتوان از GAN ها برای سناریوهایی استفاده کرد که نیاز به ایجاد چیز جدیدی از داده های موجود دارند. این می تواند شامل برنامه های بومی سازی و مسیریابی باشد، جایی که یک شبکه مولد در GAN مسیرهای بالقوه بین دو نقطه را تولید می کند، در حالی که تشخیص دهنده مشخص می کند که کدام مسیرها مناسب به نظر می رسند. GAN ها همچنین برای توسعه خدمات برای افراد کم بینا، مانند مبدل های تصاویر به صدا با استفاده از هردو GAN، برای تولید متون توصیفی از یک تصویر داده شده و یک مدل DL دیگر برای انجام تبدیل متن به گفتار، بسیار مفید هستند. در یک تحقیق پردازش تصویر با استفاده از GAN ها، تعداد زیادی از عکس های مشهور واقعی برای ایجاد تصاویر جعلی جدید مورد تجزیه و تحلیل قرار گرفته است به طوری که یک انسان نمی تواند تشخیص دهد که آیا آنها تصاویر واقعی هستند یا خیر.
7) ماشین محصور بولتزمن (RBM):
RBM یک ANN تصادفی است که از دو لایه تشکیل شده است: یک لایه قابل مشاهده که حاوی ورودی است که ما می دانیم و یک لایه پنهان که حاوی متغیرهای نهفته است. محدودیت در RBM ها در اتصال نورون ها نسبت به ماشین بولتزمن اعمال می شود. RBM ها باید یک نمودار دو بخشی ایجاد کنند، بگونهای که هر نورون قابل مشاهده باید به همه نورون های پنهان متصل شود و برعکس، اما هیچ ارتباطی بین هر دو واحد در یک لایه وجود ندارد. علاوه بر این، واحد تمایز به همه نورون های مرئی و پنهان متصل است. RBM ها را میتوان انباشته کرد تا DNN ها را تشکیل دهند. آنها همچنین ساختمان شبکه های عمیق باور هستند.
داده های آموزشی به واحدهای قابل مشاهده اختصاص داده می شود. روش آموزش میتواند از الگوریتم های انتشار بازگشتی و شیب برای بهینه سازی وزن شبکه استفاده کنند. هدف از آموزش RBM به حداکثر رساندن محصول تمام احتمالات واحدهای قابل مشاهده است. عملکرد RBM شبیه AE است، زیرا برای محاسبه متغیرهای نهفته از تغذیه پیشرو استفاده می کند، که به نوبه خود برای بازسازی ورودی با استفاده از تغذیه پسرو مناسب است. ساختار یک RBM در شکل 13 نشان داده شده است.
RBM ها می توانند ویژگی ها را از داده های ورودی استخراج کنند. این امر از طریق مدل سازی توزیع احتمال روی مجموعه ای از ورودی ها که در مجموعه واحدهای پنهان نشانده شده است اتفاق می افتد. بعنوان مثال، با داشتن مجموعه ای از فیلم های مورد علاقه افراد، یک مدل RBM میتواند دارای یک لایه قابل مشاهده باشد که از تعداد نورون ها به اندازه تعداد فیلم های موجود تشکیل شده و یک لایه پنهان متشکل از سه نورون برای نشان دادن سه ژانر مختلف مانند درام، اکشن و کمدی بکار گرفته شود.
بنابراین، بر اساس برنامه میتوان لایه پنهان را لایه خروجی درنظر گرفت؛ یا میتوان آن را با یک لایه طبقه بندی اضافی برای انجام طبقه بندی بر اساس ویژگی های استخراج شده تکمیل کرد. از انواع برنامه های کاربردی بالقوه که در آن میتوان از RBM استفاده کرد، می شود به بومی سازی داخلی، پیشبینی مصرف انرژی، پیش بینی تراکم ترافیک، آنالیز وضع حمل و معمولا هر برنامه ای را که از استخراج مهمترین ویژگی های موجود در دسترس باشد، نام برد.
8) شبکه عمیق باور (DBN):
DBN ها نوعی از ANN های مولد هستند که از یک لایه قابل مشاهده (مربوط به ورودی ها) و چندین لایه پنهان (مربوط به متغیرهای نهفته) تشکیل شده است. آنها می توانند بازنمایی سلسله مراتبی از داده های آموزشی را استخراج کرده و داده های ورودی آنها را بازسازی کنند. برای کارهای مربوط به پیشبینی میتوان از اضافه کردن یک لایه طبقه بندی کننده مانند softmax استفاده کرد.
شکل 14 ساختار یک شبکه عمیق باور، فلش های نقطه چین مسیر استخراج ویژگی ها و فلش های ممتد مسیر تولید را نشان می دهند.
آموزش یک DBN بصورت لایه ای انجام می شود، بگونه ای که هرلایه بعنوان RBM که در بالای لایه آموزش دیده قبلی آموزش دیده است، درمان می گردد. این مکانیسم یک DBN را به یک الگوریتم کارآمد و سریع در DL تبدیل می کند. برای یک لایه مخفی در DBN ، لایه پنهان RBM قبلی به عنوان لایه ورودی عمل می کند. شکل 14 ساختار یک DBN معمولی را نشان می دهد. برنامه های کاربردی متعددی میتوانند از ساختار DBN استفاده کنند، مانند طبقه بندی تشخیص اشتباه در محیط های صنعتی، شناسایی تهدید درسیستم های هشدار امنیتی و استخراج ویژگی های احساسی از تصاویر.
9) شبکه های نردبانی:
شبکه های نردبان در سال 2015 توسط والپولا و همکاران برای پشتیبانی از یادگیری بدون نظارت پیشنهاد شد. بعدا، آنها به کار در تنظیمات نیمه نظارت شده گسترش یافته و عملکرد فوقالعاده ای را برای چندین کار، مانند شناخت ارقام دست نویس و طبقه بندی تصویر نشان داده شده، گمارده شده اند.
معماری شبکه نردبانی از دو رمزگذار و یک رمزشکن تشکیل شده است. رمزگذارها به عنوان بخش نظارت شده در شبکه عمل می کنند و رمزشکن، یادگیری بدون نظارت را انجام می دهد. یکی از رمزگذارها بنام رمزگذار پاک، محاسبات عادی را تولید می کند، در حالی که رمزگذار دیگر بنام رمزگذار خراب، صدای گاوس را به همه لایه ها اضافه می کند.
رمزشکن با استفاده از یک تابع denoising می تواند بازنمایی ها را در هرلایه با توجه به داده های خراب مربوطه بازسازی کند. تفاوت بین داده های بازسازی شده و تمیز در هرلایه برای محاسبه هزینه دفع denoising آن لایه استفاده می شود. در سمت رمزگذار، تابع هزینه از تفاوت بین خروجی خراب لایه های رمزگذار و خروجی های تمیز مربوطه استفاده می کند. هدف آموزش به حداقل رساندن مبلغ هزینه در بخش نظارت شده و شبکه بدون نظارت است.
ارزیابی تجربی اولیه شبکه های نردبانی محدود به برخی از کارهای استاندارد است، مانند طبقه بندی رقم های دست نویس بر روی مجموعه داده های تغییر یافته موسسه ملی استاندارد و فناوری (MNIST) یا وظایف تشخیص تصویر در مجموعه داده های موسسه تحقیقات پیشرفته کانادا (CIFAR).
اگرچه این امر در سناریوهای IoT به طور گسترده ای مورد استفاده قرار نگرفته است، اما شبکه های نردبانی این پتانسیل را دارند که در بسیاری از تجزیه و تحلیل های IoT مبتنی بر بینایی استفاده کنند، جایی که نظارت نیمه نهایی یک امتیاز عالی است. شکل 15 ساختار شبکه نردبانی را نشان می دهد.
ب) معماری سریع و واقعی در زمان واقعی DL
این تحقیق برای تجزیه و تحلیل سریع و در زمان واقعی با استفاده از مدل های DL بر روی جریان داده ها کار میکند، اما هنوز در مراحل ابتدایی خود قرار دارد. کار اولیه در این زمینه که از ANN استفاده میکند توسط لیانگ و همکاران انجام شده است. این شبکه، شبکه های یادگیری افراطی (ELM) را گسترش داده است تا الگوریتم یادگیری پی در پی آنلاین را در شبکه های بازخورد لایه ای پنهان قرار دهند. چارچوب آنها، موسوم به OS-ELM ، داده های آموزش را یک به یک و تکه به تکه می آموزد و فقط داده های تازه وارد شده روند آموزش را طی خواهند کرد. این معماری پایه ای برای سیستم اجرای ساخت زمان واقعی است که در آن پیشنهاد شده است. در این کار، OS-ELM برای بومی سازی اشیا کف فروشگاه با استفاده از فناوری RFID مورد استفاده قرار گرفته است. زو و همکارانش همچنین از
استفاده از این معماری برای یک الگوریتم بومی سازی داخلی بر اساس اثر انگشت WiFi استفاده کرده اند، که در آن مدل OS-ELM می تواند تغییرات محیطی پویا را تحمل کند در حالی که هنوز دقت خوبی را نشان می دهد.
برای شبکه های پیچیده، معماری ارائه شده توسط رن و همکاران، با نام R-CNN سریعتر (مبتنی بر Fast RCNN)، با هدف کشف اشیا موجود در تصاویر در زمان واقعی شکل می گیرد. تشخیص شیء در تصاویر به محاسبات بیشتری احتیاج دارد و از این رو در مقایسه با کارهای طبقه بندی تصویر، انرژی بیشتری مصرف میکند، زیرا این سیستم تعداد زیادی از پیشنهادات بالقوه شی را دارد که باید ارزیابی شوند. معماری پیشنهادی مبتنی بر استفاده از الگوریتم های پیشنهادی منطقه در CNN های کامل است که پیشبینی مرزهای اشیا و محاسبه نمره عینیت را در هر موقعیت همزمان انجام می دهند.
ارزیابی آنها از معماری تشخیص اشیا پیشنهادی نشان می دهد که زمان اجرای سیستم بین 5 – 17 فریم در ثانیه (fps) است. با توجه به اینکه فریم های ورودی اصلی مجدد ا اندازهگیری می شوند به طوری که کوتاه ترین ضلع تصویر 600 پیکسل خواهد بود. مائو و همکاران همچنین از Fast R-CNN برای سیستم عامل های تعبیه شده استفاده کرده اند که گزارش از زمان اجرا 1:85 فریم در ثانیه با فریم های کوچک شده به 600 پیکسل در کوتاه ترین سمت در پلتفرم CPU + GPU تعبیه شده اند، همچنین نشان داده شده است که با تاثیر نزدیک به زمان واقعی اجرا، انرژی کافی دارند. با این حال، برای کارهای پردازش تصویر، وقتی میتوان با سرعت 30 فریم در ثانیه یا بهتر پردازش و تجزیه و تحلیل کرد، می توان رویکردی را واقعی دانست. ردمون و همكاران، سیستم You Only Look Once (YOLO) را كه براي عملكرد 45 فریم در ثانیه براي تصاویر ورودي به 448 * ized 448 رسیده است، توسعه داده اند و حتي نسخه كوچك تر آن، که Fast YOLO نام دارد، با دستیابي به 155 فریم در ثانیه، براي دوربین های هوشمند مناسب بنظر می رسد.
ج) DL مشترک با سایر رویکردها
معماری DL همچنین در سایر روش های یادگیری ماشینی به طور مشترک مورد استفاده قرار گرفته است تا کارایی آنها را بیشتر کند. تقریب عملکرد غیرخطی مدل های DL که می تواند هزاران یا حتی میلیاردها پارامتر را پشتیبانی کند، انگیزهای قوی برای استفاده از این روش در سایر روش های یادگیری ماشینی است که به چنین توابعی نیاز دارند. علاوه بر این، استخراج ویژگی های خودکار در مدل های عمیق یکی دیگر از دلایل ایجاد انگیزه برای بهره برداری از این مدل ها به طور مشترک با روش های دیگر است. همچنین در زیرشاخه های آن، خلاصه ای از چنین رویکردهایی که برای سناریوهای IoT مناسب است ارائه شده است.
1) آموزش تقویت عمیق:
آموزش تقویتی عمیق (DRL) ترکیبی از یادگیری تقویتی (RL) با DNN است. این هدف برای ایجاد عوامل نرم افزاری است که می توانند به تنهایی یاد بگیرند که سیاست های موفقی را برای به دست آوردن حداکثر پاداش های بلند مدت ایجاد کنند. در این روش، RL بهترین مدل اقدامات را نسبت به مجموعه ای از عبارات در یک محیط از یک مدل DNN می یابد. نیاز به DNN در یک مدل RL زمانی آشکار می شود که محیط زیرین توسط تعداد زیادی از عبارات فراهم باشد. در چنین شرایطی، RL سنتی به اندازه کافی کارآمد نیست. درعوض، یک مدل DL می تواند برای ارزش عمل برنامه ریزی شده تا به منظور برآورد کیفیت یک عمل در یک حالت معین استفاده شود. سیستم هایی که از DRL در بطن خود استفاده می کنند در مراحل ابتدایی خود هستند، اما قبلا نتایج بسیار امیدوارکننده ای را نشان داده اند. در زمینه IoT ، کارهای ارائه شده در استفاده از DRL در یک محیط نیمه نظارت شده برای بومی سازی محیط های دانشگاهی هوشمند استفاده می گردند. هدف از این کار، بومیسازی کاربران بر اساس سیگنال های دریافت شده از چندین iBeacons بلوتوث کم انرژی (BLE) است. عامل یادگیری از DRL استفاده میکند تا بهترین عملکرد را برای انجام دادن پیدا کند (به عنوان مثال، حرکت از جهتی مانند شمال، شمال غربی و… از نقطه شروع). عملکرد پاداش معکوس، خطای فاصله نسبت به یک هدف از پیش تعریف شده است، به گونه ای که عامل یادگیری با نزدیک شدن به هدف مورد نظر خود و برعکس، پاداش بیشتری دریافت می کند. شکل 16 نتیجه نمونه ای از چنین روش هایی را نشان می دهد؛ وقتی که یک مدل DNN به کسب جوایز بیشتر در یک محیط نیمه نظارت شده (شکل زیرین سمت چپ در شکل 16) و تعبیر پاداش آن به دقت (شکل زیرین راست) کمک می کند.
2) انتقال یادگیری با مدل های عمیق:
یادگیری انتقال که در حوزه سازگاری دامنه و یادگیری چند کاره قرار دارد، شامل انتقال و بهبود یادگیری در یک دامنه جدید همراه با انتقال بازنمایی دانش است که از دادههای یک دامنه مرتبط آموخته شده است. یادگیری انتقال برای بسیاری از برنامه های IoT یک راه حل بالقوه جالب است که جمع آوری داده های آموزشی در این زمینه کار ساده ای نیست. بعنوان مثال، با توجه به آموزش یک سیستم بومی سازی از طریق اثر انگشت BLE یا WiFi با استفاده از تلفن های هوشمند، مقادیر RSSI در همان زمان و مکان برای سیستم عامل های مختلف (به عنوان مثال، iOS و Android) متفاوت است. اگر یک مدل آموزش دیده برای یک پلتفرم خاص داشته باشیم، این مدل میتواند بدون جمع آوری مجدد مجموعه ای دیگر از داده های آموزشی برای پلتفرم جدید به سکوی دیگر منتقل شود.
مدلهای DL به دلیل توانایی یادگیری بازنمایی های سطح پایین و انتزاعی از داده های ورودی، بخوبی در انتقال یادگیری همسان هستند. به طور خاص، نشان داده شده است که رفع اختلالات انباشته شده و سایر تغییرات AE در این زمینه عملکرد بسیار خوبی دارند. انتقال یادگیری با DNN هنوز یک زمینه تحقیقاتی در حال انجام و فعال در جامعه هوش مصنوعی است و ما برنامه های گزارش شده در دنیای واقعی را در IoT ندیده ایم.
3) الگوریتم های یادگیری آنلاین با DL مشترک:
از آنجا که جریان داده های حاصل از برنامه های IoT برای تجزیه و تحلیل از سیستم عامل های ابری عبور می کند، نقش الگوریتم های یادگیری ماشین آنلاین برجسته تر می شود، زیرا نیاز است تا مدل آموزش توسط حجم افزایشی داده ها به روز شود. این امر برخلاف آنچه که فناوری های فعلی پشتیبانی می کند، مبتنی بر تکنیک های یادگیری دسته ای است، جایی که کل مجموعه داده های آموزشی باید برای آموزش در دسترس باشد و پس از آن، مدل آموزش دیده نمیتواند با داده های جدید تکامل یابد. چندین اثر تحقیق از تکنیک های یادگیری آنلاین در مدل های مختلف DL گزارش می دهند؛ ازجمله AE های رفع اختلال انباشته شده، شبکه های جمع محصول و RBM .
د) چارچوب
رشد سریع علاقه به استفاده از معماری های DL در حوزه های مختلف با معرفی چندین چارچوب DL در سالهای اخیر پشتیبانی شده است. هر چارچوب براساس معماری های پشتیبانی شده DL، الگوریتم های بهینه سازی و سهولت توسعه و استقرار قدرت خود را دارد. چندین مورد از این چارچوب ها برای آموزش کارآمد DNNها در تحقیقات گسترده استفاده شده است. در این بخش برخی از این چهارچوب ها را مرور میکنیم.
H2O :H2O یک چارچوب یادگیری ماشینی است که رابط هایی را برای R ،Python ،Scala، Java ،JSON و CoffeeScript / JavaScript فراهم می کند. H2O را می توان در حالت های مختلف از جمله حالت مستقل، در Hadoop یا در Spark Cluster اجرا کرد. علاوه بر الگوریتم های یادگیری رایج ماشین، H2O شامل اجرای یک الگوریتم DL است که براساس شبکه های عصبی تغذیه پیشرو برنامه ریزی شده است و آنرا میتوان توسط SGD با استفاده از روش انتشار بازگشتی آموزش داد. DL AE H2O بر پایه معماری عصبی عمیق (چند لایه) است، که در آن بجای اینکه تجمع لایه به لایه اطلاعات را داشته باشیم، کل شبکه دادهها را همزمان می گیرند.
Tensorflow: در ابتدا برای پروژه Google Brain ایجاد شد، Tensorflow یک کتابخانه منابع باز برای سیستم های یادگیری ماشینی با استفاده از انواع مختلف DNN است. این محصول توسط بسیاری از محصولات Google ازجملهGoogle Search ، Google Maps و Street View ، Google Translate ، YouTube و برخی محصولات دیگر استفاده میشود. Tensorflow از ساخت نمودارها برای ایجاد مدل های شبکه عصبی استفاده می کند. توسعه دهندگان همچنین می توانند از TensorBoard که بسته ای برای تجسم مدل های شبکه عصبی و مشاهده روند یادگیری از جمله بهروز کردن پارامترها است، استفاده کنند. Keras2 همچنین سطح بالایی از انتزاع برنامه نویسی را برای Tensorflow فراهم می کند.
Torch :Torch یک چارچوب منابع باز برای یادگیری ماشین است که شامل طیف گسترده ای از الگوریتم های DL برای توسعه آسان مدل های DNN می شود. این زبان با برنامه نویسی Lua ساخته شده است تا برای آموزش الگوریتم های DL سبک و سریع باشد. این توسط چندین شرکت و آزمایشگاه تحقیقاتی مانند گوگل، فیسبوک و توییتر استفاده می شود؛ همچنین از توسعه مدل های یادگیری ماشینی برای هر دو CPU و GPU پشتیبانی کرده و بسته های موازی سازی قدرتمندی را برای آموزش DNN ها فراهم می کند.
Theano: یک چارچوب مبتنی بر پایتون منبع باز برای الگوریتم های یادگیری کارآمد ماشین است که از کامپایل برای CPU و GPU پشتیبانی می کند. از کتابخانه CUDA در بهینه سازی کدهای پیچیده مورد نیاز برای اجرای GPU ها استفاده می شود؛ همچنین این امکان را به شما می دهد تا در پردازنده ها موازی سازی کنید. Theano از نمایش نمودار برای عبارات ریاضی نمادین استفاده می کند. ازطریق این بازنمایی، از تمایز نیز در عبارات نمادین ریاضی Theano پشتیبانی می شود. چندین بسته بندی ازجمله Pylearn2 ،Keras و Lasagne تجربه برنامه نویسی آسان تری را روی Theano ارائه داده اند.
Caffe: یک چارچوب منبع باز برای الگوریتم های DL و مجموعه ای از مدل های مرجع بوده و مبتنی بر C ++ است، از CUDA برای محاسبات GPU پشتیبانی کرده و رابط هایی را برای Python و Matlab فراهم می کند. Caffe نمایندگی مدل را از بخش های اجرایی آن جدا می کند. این امر با تعیین مدل ها توسط پیکربندی ها بدون کدگذاری آنها در کد منبع امکان پذیر است. جابجایی بین پلتفرم ها (بعنوان مثال، CPU به GPU یا دستگاه های تلفن همراه) بسیار ساده و فقط با تغییر یک پرچم امکان پذیر است.
سرعت آن در GPU اینگونه گزارش شده است: 1 ms / در تصاویر برای پیش بینی و 4 ms / در تصاویر برای آموزش.
چهارچوب: Neon DL منبع باز دیگریست که مبتنی بر پایتون بوده و از عملکرد بالایی برای DNN های مدرن مانند AlexNet ، گروه ویژوال هندسی (VGG) و GoogleNet برخوردار است. این برنامه از توسعه چندین مدل متداول مانند CNN ، RNN ، LSTM و AE در هر دو CPU و GPU پشتیبانی می کند. این لیست در حال گسترش است زیرا آنها GAN ها را برای یادگیری نیمه نظارت شده با استفاده از مدل های DL پیاده سازی می کنند. همچنین از تغییر آسان سکوی سخت افزاری نیز پشتیبانی می کند.
بهرام پور و همکارانش مطالعه ای مقایسه ای را برای چهار ابزار فوق الذکر یعنی Caffe ،Neon، Theano و Torch ارائه داده اند. اگرچه عملکرد هر ابزار در سناریوهای مختلف متفاوت است، اما Torch و Theano بهترین عملکرد را در اکثر سناریوها نشان دادند. یکی دیگر از معیارهای دیگر در مقایسه عملکردها، عملکرد Caffe ،TensorFlow ،Tor ،CNTK و MXNet است. جدول II چارچوب های مختلف DL را خلاصه و مقایسه می کند.
ه) درس آموختههای این بخش
ما چندین معماری معمول DL را مرور کردیم که می توانند در مؤلفه تحلیلی برنامه های مختلف IoT خدمت کنند. بیشتر این معماری ها با انواع مختلف داده های ورودی تولید شده توسط برنامه های IoT کار می کنند. با این حال، برای بدست آوردن عملکرد بهتر از داده های سریالی زمانی، RNN ها و تغییرات آنها توصیه می شوند. بطور خاص، برای وابستگی های طولانی مدت بین نقاط داده، LSTM بدلیل داشتن مفهوم دروازه برای سلول های حافظه مطلوب تر است. برای مواردی که داده های ورودی دارای بیش از یک بعد باشند، تغییرات CNN بهتر عمل میکنند. RBM ،DBN، و تنوع AE در مقابله با کاهش ابعاد بالا و استخراج ویژگی سلسله مراتبی عملکرد خوبی دارند. در ترکیب با یک لایه طبقه بندی، میتوان از آنها برای انواع سناریوهای تشخیص و پیشبینی استفاده کرد. انتظار می رود معماری های جدیدتری از جمله VAE ،GAN و Ladder Networks تأثیر زیادی روی برنامه های IoT داشته باشند؛ زیرا یادگیری نیمه نظارت شده را تحت پوشش قرار می دهند. این موارد برای برنامه های IoT در جایی که حجم عظیمی از داده ها تولید می شوند، در حالی که بخش کوچکی از آن برای یادگیری ماشین قابل یادداشت است، مطلوب تر هستند. جدول I معماری DL را خلاصه می کند.
چند تلاش برای سریعتر کردن و سریع پاسخ دادن به معماری DL نیز مورد بحث قرار گرفت. این عرصه به اکتشافات و تحقیقات بیشتری نیاز دارد تا در بسیاری از برنامه های IoT حساس به زمان قابل اجرا باشد. معماری ها و تکنیکه ای یادگیری ماشین های در حال ظهور که هر دو از DL بهرمند می شوند و الزامات خاص برنامه IoT را برطرف می کنند نیز برجسته شده اند. درواقع، DRL می تواند از استقلال برنامه های IoT پشتیبانی کند، یادگیری انتقال می تواند شکاف عدم وجود مجموعه داده های آموزشی را پر کند، و یادگیری آنلاین با نیاز به تجزیه و تحلیل داده های استریم IoT مطابقت دارد.
ما همچنین چندین چارچوب معمول و قدرتمند را برای توسعه مدل های DL بررسی کردیم. برای برنامه های IoT ، زمان آموزش، زمان اجرا و بروزرسانی پویای مدل های آموزش دیده عوامل تعیین کننده یک ماژول تحلیلی مطمئن و کارآمد را تشکیل می دهند. بیشتر چارچوب های فعلی بجای “تعریف اجرا” از الگوی “تعریف و اجرا” پیروی می کنند. اولی اجازه بروزرسانی پویا از مدل را نمی دهد در حالی که دومی از چنین اصلاحاتی پشتیبانی می کند. زنجیر، چارچوبی است که از الگوی دوم پیروی می کند و می تواند تغییرات پویای مدل را کنترل کند.
برنامه DL در IOT
روش های DL باوجود نتایج آزمایشی در چندین زمینه مانند پردازش سیگنال، پردازش زبان طبیعی و تشخیص تصویر امیدوارکننده است. این روند در IoT های عمودی روبه افزایش است. برخی از مدل های شبکه عصبی در حوزه های خاص بهتر عمل می کنند. بعنوان مثال، شبکه های کانوشنال عملکرد بهتری را در برنامه های مربوط به بینایی ارائه می دهند، در حالی که AE ها با تشخیص ناهنجاری، دفع داده ها و کاهش ابعادی برای تجسم داده ها عملکرد بهتری دارند. این ارتباط بین نوع و مدل شبکه های عصبی که به بهترین وجه متناسب با هر یک از حوزه های مختلف برنامه هستند، بسیار مهم است.
در این بخش، برنامه های موفق DL را در حوزه های IoT مرور می کنیم. براساس مشاهدات ما، بسیاری از برنامه های مرتبط با IoT بعنوان سرویس هوشمند پایه خود از طبقه بندی بینایی و تصویر استفاده می کنند (مانند تشخیص علائم راهنمایی و رانندگی یا تشخیص بیماری های گیاهی که در بخش IV-B در مورد آنها صحبت خواهیم کرد). خدمات دیگری نیز وجود دارد، مانند تشخیص انسان که برای برنامه های خانه هوشمند یا دستیار ماشین هوشمند استفاده می شوند. ما انواع مختلفی از این سرویس ها را بعنوان خدمات اساسی که بر روی آنها دیگر برنامه های IoT ساخته شده است، شناسایی می کنیم. ویژگی مشترک این سرویس ها این است که بجای اینکه داده های خود را برای تجزیه و تحلیل های بعدی جمع کرده باشند، باید مانند یک حالت تحلیلی سریع رفتار کنند. درواقع، هر دامنه ممکن است سرویس های خاص و فراتر از این خدمات اساسی داشته باشد. شکل 17 خدمات اساسی و برنامه های IoT را روی آنها نشان می دهد. در بخش های زیر، ما ابتدا خدمات بنیادی IoT را بررسی می کنیم که از DL بعنوان موتور اطلاعاتی خود استفاده می کنند، سپس برنامه ها و دامنه های IoT را برجسته می کنیم که در آنها ترکیبی از خدمات بنیادی و همچنین خدمات خاص ممکن است مورد استفاده قرار گیرند.
الف) خدمات بنیادی
1) تشخیص تصویر:
بخش بزرگی از برنامه های IoT ، سناریوهایی را نشان می دهند که داده های ورودی برای DL به صورت فیلم یا تصاویر است. دستگاه های تلفن همراه همه کاره و مجهز به دوربین های با وضوح بالا، تولید تصاویر و فیلم ها را توسط هم، در همه جا تسهیل می کنند. علاوه براین، دوربین های فیلمبرداری هوشمند در بسیاری از مکان ها مانند خانه های هوشمند، دانشگاه ها و تولیدی ها برای برنامه های مختلف استفاده می شوند. تشخیص یا طبقه بندی تصاویر و اشیا، از جمله کاربردهای اساسی چنین دستگاه هاییست.
مسئله ای که در مورد سیستم های مرتبط با IoT که به شناخت تصاویر پرداخته، استفاده از مجموعه داده های منابع خاص برای ارزیابی عملکرد آنهاست. بیشتر این سیستم ها از مجموعه داده های موجود در تصاویر مشترک مانند مجموعه داده های MNIST همچون دست نوشته ها، مجموعه داده های چهره VGG ، CIFAR-10 و CIFAR-100 ، مجموعه داده های کوچک تصاویر و… استفاده می کنند. اگرچه برای مقایسه با رویکردهای دیگر خوب است، اما این مجموعه داده ها ویژگی های خاصی از سیستم های IoT را نشان نمی دهند. بعنوان مثال، ورودی برای کار تشخیص خودرو در اتومبیل های متصل هوشمند همیشه یک تصویر واضح نخواهد بود، زیرا مواردی وجود دارد که تصویر ورودی در شب یا در هوای بارانی یا مه آلود باشد. این موارد از طریق مجموعه داده های موجود رسیدگی نمی شود و از اینرو مدل هایی که بر اساس این مجموعه داده ها آموزش دیده اند به اندازه کافی جامع نیستند.
2) تشخیص گفتار / صدا:
با گسترش دستگاه های تلفن همراه هوشمند و پوشیدنی، تشخیص خودکار گفتار به روشی طبیعی و راحتتر برای تعامل مردم با دستگاه های خود تبدیل می شود. همچنین اندازه کوچک دستگاه های تلفن همراه و پوشیدنی ها، امروزه احتمال داشتن صفحه نمایش لمسی و صفحه کلید را بعنوان وسیله ورودی و تعامل با این دستگاه ها کاهش می دهد. با اینحال، نگرانی اصلی برای ارائه قابلیت تشخیص گفتار/ صدا در دستگاه های دارای محدودیت منابع، شدت انرژی آن است، به ویژه هنگامی که داده ها از طریق شبکه های عصبی پردازش می شوند. در یک مدل شبکه عصبی به رسمیت شناختن گفتار، داده های صوتی بعنوان ورودی خام به شبکه نمایش داده می شوند. داده ها از طریق لایه های پنهان پردازش می شوند و احتمال تبدیل داده های صوتی به صدای گفتار خاص در لایه خروجی ارائه می شود.
پرایس و همکاران گزارش داده اند که برای تشخیص خودکار گفتار، یک تراشه DL کم مصرف ویژه برای هدف قرار داده اند. تراشه تخصصی جدید انرژی کمی بین 0.2 تا 10 میلی وات، یعنی 100 برابر کمتر از مصرف انرژی برای اجرای ابزار تشخیص گفتار در تلفن های همراه فعلی را مصرف می کند.
در تراشه جدید، DNN برای تشخیص گفتار اجرا شده است. بمنظور صرفه جویی در مصرف انرژی، سه سطح تشخیص فعالیت صوتی با سه شبکه عصبی جداگانه طراحی شده است که هرکدام دارای سطح پیچیدگی متفاوتی هستند. کمترین پیچیدگی شبکه، در نتیجه کمترین میزان انرژی با کنترل نویز در محیط، فعالیت صوتی را تشخیص می دهد. اگر این شبکه صدا را شناسایی کند، تراشه شبکه تشخیص سطح پیچیدگی بعدی را اجرا میکند که وظیفه آن مدل سازی صوتیست تا تشخیص دهد که صدا مانند گفتار است. اگر خروجی این شبکه از میزان رضایت بخشی بالایی برخوردار باشد، پس از شناسایی شبکه های سوم، با داشتن بیشترین میزان مصرف انرژی برای شناسایی کلمات مجزا راه اندازی می شود.
3) بومی سازی داخلی:
ارائه خدمات آگاهی از موقعیت مکانی، از جمله ناوبری داخلی و بازاریابی آگاهی از مکان نمایندگی ها، در محیط های داخلی رواج دارد. بومی سازی داخلی ممکن است برنامه هایی در سایر بخش های IoT ،مانند خانه های هوشمند، خوابگاههای هوشمند یا بیمارستان ها داشته باشد. داده های ورودی حاصل، از چنین برنامه هایی مانند دید، ارتباط قابل مشاهده با نور (VLC)، مادون قرمز، سونوگرافی،WiFi ،RFID، باند ultrawide و بلوتوث حاصل می شوند. برای رویکردهای مبتنی بر WiFi یا بلوتوث، بیشتر ادبیات از تلفن های همراه برای دریافت سیگنال از فرستنده ثابت (یعنی نقاط دسترسی یا iBeacons) استفاده کرده اند که به آنها اثرانگشت می گویند. درمیان این رویکردهای اثرانگشت، چندین تلاش از استفاده از مدل های DL برای پیشبینی مکان خبر داد.
از DL باموفقیت برای یافتن موقعیت های داخلی با دقت بالا استفاده شده است. در سیستمی بنام DeepFi از یک روش DL برای انگشت نگاری از داده های اطلاعات کانال WiFi در راستای شناسایی موقعیت های کاربر استفاده شده است. این سیستم شامل آموزش آفلاین و مراحل بومی سازی آنلاین است اما در مرحله آموزش آفلاین، DL برای آموزش کلیه وزن ها بر اساس اثر اطلاعات اثر انگشت کانال قبلا ذخیره شده، مورد سوء استفاده قرار می گیرد. این آزمایشات ادعا می کنند که تعداد لایه ها و واحدهای پنهان در مدل های DL تأثیر مستقیمی بر صحت بومی سازی دارد. در CNN برای بومی سازی داخلی از تلفیق داده های سنجش مغناطیسی و بینایی استفاده می شود. علاوه بر این، یک CNN برای تعیین موقعیت های داخلی کاربران با تجزیه و تحلیل تصویری از صحنه اطراف آنها آموزش دیده است.
لو و همکاران همچنین از شبکه های LSTM برای بومی سازی ربات های فوتبال استفاده کرده اند. در این نرم افزار، داده های جمع آوری شده از چندین حسگر یعنی سیستم ناوبری اینرسی (INS) و برداشت بینایی، برای پیشبینی موقعیت ربات تجزیه و تحلیل می شوند. نویسندگان گزارش داده اند که دقت و کارایی در مقایسه با دو روش پایه، یعنی استاندارد فیلتر کالمن تمدید شده استاندارد (EKF) و فیلتر ذرات استاتیک بهبود یافته است.
4) تشخیص وضعیت فیزیولوژیکی و روانی:
IoT همراه با تکنیک های DL نیز برای تشخیص حالات مختلف فیزیولوژیکی و روانشناختی انسان، از جمله ناهنجاری، فعالیت و احساسات بکار گرفته شده است. بسیاری از برنامه های IoT برای ارائه خدمات خود، بعنوان مثال خانه های هوشمند، اتومبیل های هوشمند، سرگرمی (مثلا XBox)، آموزش، توانبخشی و پشتیبانی بهداشتی، ورزشی و صنعتی، ماژولی را برای تخمین موقعیت های های بشری یا شناخت فعالیت ها داده اند. بعنوان مثال، برنامه های مناسب در خانه های هوشمند بر اساس تجزیه و تحلیل موقعیت های سرنشینان ساخته شده است. دوربین ها، فیلم های سرنشین را به یک DNN منتقل می کنند تا وضعیت شخص را پیدا کرده و بر این اساس مناسب ترین اقدام را انجام دهند. توشف و همکارانش برای دستیابی به این هدف از سیستمی بهره می گیرند که از یک مدل CNN استفاده می کند. این نوع خدمات همچنین می تواند در آموزش و پرورش برای نظارت بر توجه دانشجویان و در فروشگاه های خرده فروشی برای پیشبینی رفتار خرید مشتریان استفاده شود.
اوردنوز و همکارانش چارچوب DL را ارائه داده اند که ترکیبی از قدرت شبکه های عصبی CNN و LSTM برای تشخیص فعالیت انسانی از داده های حسگر پوشیدنی (شتاب سنج، ژیروسکوپ و…) است.
مدل آنها از چهار لایه حلقوی با ReLU ها تشکیل شده است و به دنبال آن دو لایه LSTM و یک لایه نرم افزاری وجود دارد. آنها نشان دادند كه این تركیب از یك مدل مبنا كه فقط براساس لایه های كانونشن به طور متوسط 4 درصد است، بهتر عمل می كند. تائو و همکارانش همچنین از معماری LSTM برای شناسایی فعالیت های انسانی بر اساس داده های حسگر تلفن همراه استفاده کرده اند. لی و همکارانش همچنین استفاده از داده های خام برچسب های منفعل FRID را برای تشخیص فعالیت های پزشکی در اتاق تروما (بعنوان مثال، اندازه گیری فشار خون، معاینه دهان، قرار دادن سرب قلبی و…) بر اساس CNN عمیق گزارش می دهند.
یک مدل ترکیبی از CNN و RNN برای تشخیص ژست در قاب های ویدیویی پیشنهاد شد. این مدل در مقایسه با مدل های بدون چنین ترکیبی نتایج بهتری را نشان داد و اهمیت مؤثر خود را در چنین کارهایی تأیید کرد. فراجیاداکی و همکاران یک مدل DNN به نام رمزگذار-عودکننده-رمزشکن (ERD) را برای تشخیص بدن و پیشبینی حرکت در فیلم ها و مجموعه داده های ضبط حرکت ارائه دادند. مدل پیشنهادی شامل RNN با رمزگذار قبل از لایه های مکرر و یک رمزشکن پس از آنها بود. این معماری نشان داده است که از ماشین آلات بولتزمن محدود شده شرطی (CRBMs) برای این برنامه بهتر است.
فراتر از حرکات بدنی، برآورد احساسات انسان از قاب های ویدیویی نیز در استفاده از مدلی که شامل CNN ،DBN و AE است، مورد بررسی قرار گرفته است. علاوه بر این، کار در داده های حسگر بیحرکت تلفن همراه برای تشخیص حرکت است. این تأیید کرد که الگوهای حرکت انسان می تواند بعنوان منبع شناسایی و احراز هویت کاربر استفاده شود. مدل به کار رفته در این سیستم ترکیبی از لایه های حلقوی و ساعت RNN است.
5) امنیت و حریم خصوصی:
امنیت و حفظ حریم خصوصی یک نگرانی عمده در همه حوزه ها و برنامه های IoT است. خانه های هوشمند، ITS ، صنعت، شبکه هوشمند و بسیاری از بخش های دیگر امنیت را یک نیاز اساسی می دانند. درواقع، اعتبار عملکرد سیستم ها بستگی به محافظت از ابزارها و فرآیندهای یادگیری ماشین آنها از مهاجمان دارد.
تزریق داده نادرست (FDI) نوعی حمله به سیستم های داده محور است. هی و همكاران DBN شرطی را برای استخراج ویژگی های حمله FDI از داده های پیشین شبکههای هوشمند پیشنهاد کرده و از این ویژگی ها براي شناسایي حمله در زمان واقعي استفاده كردند. اینکارهمچنین مربوط به تشخیص ناهنجاری است که ممکن است در شبکه های خودرو رخ دهد.
تلفن های هوشمند بعنوان کمک بزرگی به داده ها و برنامه های IoT نیز در معرض تهدیدات جدی حملات هکرها قرار دارند. فراتر از دغدغه های کاربران، محافظت از این دستگاه ها در برابر انواع مختلف امنیت برای چشمانداز IoT ضروری است. یوان و همکاران چارچوب DL را برای شناسایی بدافزارها در برنامههای Android پیشنهاد دادند. معماری آنها مبتنی بر DBN است که با استفاده از آن، دقت 96.5 درصد را برای شناسایی برنامه های مخرب گزارش داده اند.
حفظ امنیت و حریم خصوصی رویکردهای یادگیری عمیق ماشین، مهم ترین عوامل برای پذیرش استفاده از این روش ها در بخش IoT است. وقتی آنها مشمول یادگیری توزیع شده بودند، شکری و همكاران روش هایی را برای حل مسائل مربوط به حفظ حریم خصوصی در مدل های DL پیشنهاد می كنند.
رویکرد آنها قادر به حفظ حریم خصوصی داده های آموزشی شرکت کنندگان و همچنین صحت مدل ها در یک زمان بود. هسته اصلی رویکرد آنها مبتنی بر این واقعیت است که الگوریتم های بهینه سازی شیب نزولی تصادفی که در بسیاری از معماری های DL مورد استفاده قرار می گیرد، می تواند بصورت موازی اما ناهمزمان انجام شود. بنابراین شرکت کنندگان می توانند بطور مستقل مدل را بر روی داده های خود آموزش دهند و بخشی از پارامترهای مدل خود را با سایر شرکت کنندگان به اشتراک بگذارند. آبادی و همكاران نیز با استفاده از الگوریتم نزول شیب تصادفی خصوصی، روشی را برای تضمین حریم خصوصی پیشنهاد كردند.
ب) برنامه ها
1) خانه های هوشمند
مفهوم خانه های هوشمند طیف گسترده ای از برنامه های مبتنی بر IoT را شامل می شود که می تواند در کاهش مصرف انرژی و بهره وری خانه ها و همچنین راحتی و کیفیت زندگی ساکنین آنها نقش زیادی داشته باشد. امروزه لوازم خانگی می توانند به اینترنت وصل شوند و خدمات هوشمندی ارائه دهند.
بعنوان مثال، مایکروسافت و لیبرهردو در یک پروژه مشترک، از Cortana DL برای اطلاعات جمع آوری شده از داخل یخچال استفاده میکنند. این تجزیه و تحلیل ها و پیشبینیها میتواند به خانواده کمک کند تا کنترل بهتری در مورد منابع و هزینه های خانه خود داشته باشند و در کنار سایر داده های خارجی می توانند برای نظارت و پیشبینی روندهای بهداشتی مورد استفاده قرار گیرند.
بیش از یک سوم برق تولید شده در ایالات متحده توسط بخش مسکونی مصرف میشود و تجهیزات HVAC و دستگاه های روشنایی بزرگترین منبع مصرف انرژی در میان این نوع ساختمان ها هستند. انتظار می رود با مدیریت هوشمندانه انرژی و همچنین بهبود بازده در وسایل، این تقاضا با سرعت کمتری رشد کند. از اینرو، توانایی کنترل و بهبود بهره وری انرژی و پیشبینی نیاز آینده در سیستمهای خانگی هوشمند ضروری است. در برنامه های کاربردی خانه هوشمند، پیشبینی بار الکتریکی جزو رایجترین برنامه هایی است که از شبکه های مختلف DL برای مشخص کردن وظایف استفاده می کند.
مانیک و همکاران با استفاده از سه معماری DL از جمله LSTM، توالیمند (S2S) و CNN، یک تجزیه و تحلیل مقایسه ای از پیشبینی بار برای مصرف انرژی در خانه انجام دادند. نتایج آنها نشان می دهد که LSTM S2S استفاده از آینده را بهتر از سایر معماری ها ، به دنبال آن CNN و سپس LSTM پیشبینی میکند. آنها همچنین مجموعه داده مشابه را با یک ANN معمولی مقایسه کردند و همه مدلهای فوق از مدل ANN بهتر عمل کرد.
2) شهر هوشمند:
خدمات شهری هوشمند در چندین حوزه IoT مانند حمل و نقل، انرژی، کشاورزی و… گسترش یافته است. با اینحال، این بخش از دیدگاه یادگیری ماشین جالب تر است زیرا دادههای ناهمگن حاصل از حوزه های مختلف منجر به تولید داده های بزرگ می شوند که میتواند به خروجی با کیفیت بالا هنگام تجزیه و تحلیل با استفاده از مدل های DL ختم شود. شهر هوشمند از پیشرفت در حوزه های دیگر برای دستیابی به مدیریت منابع کارآمد برای کل شهر بهره می برد. بعنوان مثال، برای بهبود زیرساخت های حمل و نقل عمومی و ارائه خدمات پیشرفته جدید، اخذ تحلیل و الگوها از رفتارهای حمل و نقل عمومی مورد توجه مقامات محلی است.
توشیبا اخیرا یک باند تست DL را به طور مشترک با Dell Technologies ایجاد کرده است و از این مجموعه تست در یک مجتمع هوشمند در کاوازاکی، ژاپن، برای ارزیابی داده های جمع آوری شده در این مرکز استفاده کرده است. هدف از اجرای این آزمایش، اندازه گیری اثربخشی استفاده از معماری های DL در اکوسیستم های IoT و شناسایی بهترین روش ها برای بهبود خدمات از جمله افزایش در دسترس بودن دستگاه ها، بهینه سازی سنسورهای مانیتورینگ و کاهش هزینه های نگهداری است. داده های بزرگی که آزمایشگاه را تغذیه می کند، از مدیریت ساختمان، تهویه هوا و امنیت ساختمان ها جمع آوری شده است.
یک مسئله مهم برای شهر هوشمند، پیشبینی الگوهای حرکت جمعیت و استفاده از آنها در حمل و نقل عمومی است. سانگ و همكاران برای دستیابی به این هدف در سطح شهر، سیستمی مبتنی بر مدل های DNN تهیه كردند. سیستم آنها بر روی یک شبکه عصبی LSTM چهار لایه ساخته شده است تا از داده های تحرک انسان (داده GPS) با حالت های انتقال حمل و نقل آنها (به عنوان مثال، ماندن، پیاده روی، دوچرخه، ماشین، قطار) یاد بگیرند.
آنها بجای پرداختن به همه این ویژگی ها، با پیشبینی وضعیت تحرک و حمل و نقل افراد بعنوان دو کار جداگانه رفتار کردند. درنتیجه، سیستم یادگیری آنها براساس معماری LSTM عمیق چند کاره ساخته شده است که بطور مشترک می توانند از دو مجموعه، ویژگی ها را یاد بگیرند. انتخاب LSTM توسط ماهیت مکانی و الگوهای تحرک انسانی انجام و هدایت میشد. نویسندگان ادعا می کنند که رویکرد آنها بر اساس LSTM عمیق چند کاره در مقایسه با هردو LSTM کم عمق که تنها یک لایه واحد دارند و همچنین LSTM های عمیق و بدون سیستم چندکاره، عملکرد بهتری دارند.
لیانگ و همکاران یک سیستم پیشبینی تراکم جمعیت را در زمان واقعی و در ایستگاه های حمل و نقل ارائه داده اند که از داده های ارتباطی کاربران تلفن همراه به عنوان سابقه جزئیات تماس گیرنده (CDR) استفاده می کند. داده های CDR هنگامی جمع می شوند که کاربر اقدام به ارتباط از راه دور (یعنی تماس، پیام کوتاه، MMS و دسترسی به اینترنت) از طریق تلفن خود انجام دهد، که معمولا شامل اطلاعات مربوط به شناسه کاربر، زمان، مکان و عملکرد ارتباطات کاربر است. آنها سیستم خود را بر اساس یک مدل RNN برای ایستگاه های مترو ساخته و پیشبینی های دقیق تری را در مقایسه با مدل های شبکه عصبی اتورگرسیوی غیرخطی گزارش دادند.
مدیریت پسماند و طبقه بندی زباله ها یکی دیگر از کارهای مرتبط با شهرهای هوشمند است. یک روش ساده برای انجام این اتوماسیون از طریق طبقه بندی مبتنی بر بینایی با استفاده از CNN های عمیق انجام میگیرد. نظارت بر کیفیت هوا و پیشبینی آلودگی، جنبه دیگری از مدیریت شهریست. لی و همکاران یک مدل پیشبینی کیفیت هوا مبتنی بر DL با استفاده از یک AE انباشته شده برای استخراج ویژگی های بدون نظارت، و یک مدل رگرسیون لجستیکی برای رگرسیون پیشبینیهای نهایی ایجاد کردند.
آماتو و همکاران، یک سیستم غیر متمرکز برای شناسایی نقاط اشغالی و خالی در پارکینگ ها با استفاده از دوربینهای هوشمند و CNN های عمیق طراحی کرده و توسعه دادند. نویسندگان، یک معماری کوچک از یک CNN را روی دوربینهای هوشمند مستقر کردهاند که مجهز به مدل Raspberry Pi 2 است.
این دستگاه های تعبیه شده در دوربینهای هوشمند میتوانند CNN را بر روی هر دستگاهی اجرا کنند تا تصاویر فضاهای پارکینگ شخصی را بصورت اشغال یا خالی طبقه بندی کنند. سپس دوربین ها فقط خروجی طبقه بندی را به سرور مرکزی ارسال می کنند. ولیپور و همکاران همچنین سیستمی را برای شناسایی نقاط مختلف پارکینگ با استفاده از CNN ایجاد کردند که در مقایسه با SVM نتایج بهتری را نشان داده است. جدول 3 تلاش های فوق را خلاصه میکند.
3) انرژی:
ارتباط دوطرفه بین مصرف کنندگان انرژی و شبکه هوشمند، منبعی برای داده های بزرگ IoT است. در این زمینه، کنتورهای هوشمند در نقش تولید داده و دستیابی به سطح دانه ریز، مصرف انرژی را اندازه گیری می کنند. ارائه دهندگان انرژی علاقهمندند که الگوهای مصرف انرژی محلی را یاد گرفته، نیازها را پیشبینی کنند و تصمیمات مناسبی را براساس تجزیه و تحلیل در زمان واقعی بگیرند. موکانو و همکارانش نوعی RBM برای شناسایی و پیشبینی انعطاف پذیری انرژی ساختمانها در زمان واقعی ایجاد کردهاند. انعطاف پذیری انرژی در مورد تغییر در مصرف برق یک خانواده و درعین حال به حداقل رساندن تاثیر بر ساکنین و کارهاست. در کار ذکر شده، زمان استفاده و مصرف لوازم شخصی برای دستیابی به کنترل انرژی منعطف پیشبینی شده است. مزیت این مدل علاوه بر نشان دادن عملکرد و دقت خوب، اینست که شناسایی انعطاف پذیری را میتوان با پیشبینی انعطاف پذیری همزمان انجام داد. دو متغیر از RBM برای پیشبینی مصرف انرژی در فواصل کوتاه مدت در خانه های مسکونی استفاده میشود. این مدل شامل RBM شرطی (CRBM) و یک RBM شرطی فاکتور شده (FCRBM) است. نتایج آنها حاکی از آن است که FCRBM عملکرد بهتری نسبت به CRBM ، RNN و ANN دارد. علاوه بر این، با گسترش افق پیشبینی، FCRBM و CRBM پیشبینی های دقیق تری نسبت به RBM و ANN نشان می دهند.
پیرو شبکه هوشمند، پیشبینی میزان مصرف انرژی از انرژی خورشیدی ، باد یا سایر منابع طبیعی انرژی پایدار یک زمینه تحقیقاتی فعال است. DL به طور فزایندهای در بسیاری از برنامه های این دامنه استفاده می شود. بعنوان مثال، جنسلر و همكاران عملکرد چند مدل DL مانند DBN ، AE و LSTM و همچنین MLP را برای پیشبینی انرژی خورشیدی 21 نیروگاه فتوولتائیك بررسی میكنند. برای پیشبینی انرژی خورشیدی، یک عنصر اصلی ورودی یک مقدار عددی برای پیشبینی هوا در یک افق زمانی معین است. از ارزیابی آنها، ترکیب AE ها و LSTM (Auto-LSTM) نشان داده شده است که بهترین نتایج را در مقایسه با سایر مدل ها و پس از آن DBN ایجاد می کنند. دلیل بدست آوردن نمره پیش بینی خوب توسط Auto-LSTM این است که آنها می توانند ویژگی هایی را از داده های خام استخراج کنند که این مورد برای ANN و MLP امکان پذیر نیست. یک سیستم پیشبینی آنلاین بر اساس LSTM برای پیشبینی توان انرژی خورشیدی 24 ساعته پیشنهاد شده است.
4) سیستم های حمل و نقل هوشمند:
داده های سیستم های حمل و نقل هوشمند (ITS) منبع دیگری از داده های بزرگ است که همه روزه و در همه جا رواج دارد. ما و همکارانش سیستم تحلیل شبکه حمل و نقل را بر اساس DL ارائه دادند.
آنها معماری های RBM و RNN را بعنوان مدل های خود در یک محیط محاسبات موازی و داده های GPS از مالیات های شرکت کنندگان بعنوان ورودی مدل ها استفاده کردند. صحت سیستم آنها برای پیشبینی تکامل ازدحام ترافیک در طی یک ساعت از داده های جمع شده تا 88 ٪ است که در کمتر از 6 دقیقه محاسبه شده است؛ همچنین تحقیقات مربوط به پیشبینی، جریان ترافیک کوتاه مدت را گزارش داد.
آنها از LSTM بعنوان الگوی یادگیری خود استفاده کرده و در مقایسه با سایر روش ها از جمله SVM، شبکه های عصبی ساده رو به جلو و AE های انباشته شده، دقت بهتری را برای LSTM نشان دادند. برای فواصل مختلف (15، 30، 45 ، و 60 دقیقه) LSTM کمترین میانگین درصد خطای مطلق (MAPE) را نشان داد. با اینحال، برای فواصل کوتاه 15 دقیقه، میزان خطای SVM کمی بیشتر از مدل LSTM است. این نتیجه را میتوان با این واقعیت تفسیر کرد که تعداد کمی از نقاط داده در فواصل کوتاه، مرزهای تفکیک کننده را برای کار طبقه بندی در مدل LSTM در مقایسه با مدل SVM ایجاد نمی کند. در یک مطالعه دیگر، داده های ITS برای بهبود امنیت ارتباطات شبکه درون خودرو در معرض یک سیستم تشخیص نفوذ مبتنی بر DNN قرار گرفته اند.
ITS همچنین به ایجاد روش های تشخیص و شناسایی علائم راهنمایی و رانندگی انگیزه می دهد. برنامه های کاربردی مانند رانندگی خودمختار، سیستم های کمک به راننده و نقشه برداری تلفن همراه برای ارائه خدمات قابل اعتماد به چنین مکانیزمهایی نیاز دارند. کرسان و همکارانش یک سیستم شناسایی علائم راهنمایی و رانندگی را بر اساس DNN های لایه های جمع کننده و حداکثر مخلوط ارائه کردند. آنها یک معماری چند ستونی DNN را معرفی کردند که شامل چندین ستون از DNN های جداگانه است و با افزایش این دقت، گزارش ها از صحت بالایی خبر دادند. ورودی، توسط چندین پردازنده مختلف پردازش شده است و تعداد ستون های تصادفی ورودی قبلی را برای پردازش دریافت می کند. پیشبینی نهایی، میانگین تمام خروجیهای DNN است. نتایج آنها نشان میدهد که این روش پیشنهادی با دستیابی به میزان شناخت 99.46 درصد، با دقت 0.62 درصد توانسته است علائم راهنمایی و رانندگی را بهتر از افراد حاضر در این کار تشخیص دهد.
این تجزیه و تحلیل ها برای اینکه در سناریوهای واقعی قابل اجرا باشد، باید در زمان واقعی انجام شوند. لیم و همکاران در تحقیقاتشان یک علامت راهنمایی و رانندگی را در زمان واقعی بر اساس پیشنهاد کرده اند که با یک پردازنده گرافیکی عمومی هدف یکپارچه شده است. آنها اندازه CNN F1 را با حداقل میزان 0.89 در نتایج خود با داده هایی که تغییراتی در روشنایی دارند گزارش کردند. برای داشتن موتور استنتاج سریعتر، آنها از CNN با دو لایه حلقوی استفاده می کردند. علاوه بر این، اتومبیل های خودران از DNN ها در انجام بسیاری از کارها مانند شناسایی عابر پیاده، علائم راهنمایی و رانندگی، موانع و… استفاده می کنند. چندین استارتآپ وجود دارند که از DL در اتومبیل های خودران برای انجام کارهای مختلف هنگام رانندگی در خیابان ها بهره میگیرند.
5) بهداشت و سلامتی:
IoT همراه با DL همچنین در ارائه راه حل های بهداشتی و درمانی برای افراد و جوامع به کار رفته است. بعنوان مثال، تهیه راه حل های مبتنی بر برنامه های تلفن همراه برای اندازه گیری دقیق رژیم های غذایی، پیگیری تحقیق است که می تواند به کنترل سلامت و رفاه افراد کمک کند. لیو و همکاران سیستمی را برای شناخت تصاویر غذایی و اطلاعات مربوط به آنها، ازجمله انواع و اندازه های آنها ایجاد کردند. الگوریتم تشخیص تصویر آنها مبتنی بر CNN است که در مقایسه با سیستم های پایه به نتایج رقابتی رسیده است.
DL برای طبقه بندی و تجزیه و تحلیل تصاویر پزشکی یک موضوع داغ در حوزه مراقبت های بهداشتی است. بعنوان مثال، پریرا و همكاران برای شناسایی بیماری پاركینسون در مراحل اولیه خود از ایده تشخیص تصاویر دستنویس توسط CNN استفاده كردند. مدل آنها ویژگی هایی را از سیگنال های یک قلم هوشمند که از حسگرها برای اندازه گیری دینامیک دست نوشته در امتحان فرد استفاده می کند، می آموزد. محمد و همکاران سیستم تشخیص آسیب شناسی صوتی را با استفاده از چارچوب های IoT و ابری پیشنهاد می کنند که در آن سیگنال های صوتی بیماران از طریق دستگاه های حسگر ضبط می شوند و برای تجزیه و تحلیل به یک سرور ابری ارسال می گردند. آنها برای تشخیص آسیبشناسی از یک دستگاه فوق آموزش دیده توسط سیگنال های صوتی استفاده کردند. DL برای تشخیص بیماریهای قلبی و عروقی از طریق ماموگرافی ها استفاده شد. آنها یک CNN با دوازده لایه ایجاد کردند تا وجود BAC را در بیمار تشخیص دهند. نتایج آنها نشان می دهد که دقت مدل DL آنها به اندازه متخصصان انسانی خوب است. اگرچه این کار بصورت آفلاین انجام شده است، اما پتانسیل توسعه یا گسترش دستگاه های ماموگرام در زمینه های IoT برای تشخیص آنلاین و زودهنگام چنین بیماری هایی را نشان میدهد.
فنگ و همكاران استفاده از RBM ها و DBN ها را براي تشخیص سقوط در محیط مراقبت از منزل گزارش می كنند درحالیکه حالت های معمولی در چنین محیطی ایستاده، نشسته، خم و بعضا دروغگو هستند. دراز کشیدن روی زمین بیش از یک آستانه مشخص، بعنوان یک وضعیت افتاده درنظر گرفته می شود؛ عدم وجود مجموعه دادهه ای بزرگ و انجام تشخیص آفلاین، ازجمله محدودیت های آنهاست.
محققان همچنین از داده های پزشکی سری زمانی در رابطه با مدل های مبتنی بر RNN برای تشخیص زودهنگام و پیشبینی بیماریها استفاده کردند. لیپتون و همکاران عملکرد شبکههای LSTM را بمنظور تجزیه و تحلیل و تشخیص الگوهای سری های زمانی چند متغیره پزشکی در بخش مراقبت های ویژه (ICU) بررسی کردند. داده های ورودی در سیستم آنها از ورودی های حسگر علائم حیاتی و همچنین نتایج آزمایشگاهی تشکیل شده است. نتایج عملکرد آنها نشان میدهد که یک مدل LSTM که براساس داده های سری زمانی خام شکل گرفته، از شبکه MLP بهتر است.
6) کشاورزی:
تولید محصولات زراعی سالم و ایجاد راه های کارآمد برای رشد گیاهان، یکی از نیازهای جامعه سالم و محیط پایدار است. تشخیص بیماری در گیاهان با استفاده از DNN ، مسئله ایست که ثابت کرده که یک راه حل مناسب است. در مطالعه ای که توسط لاجویچ و همکاران گزارش شده است، نویسندگان سیستم تشخیص بیماری های گیاهی را بر اساس طبقه بندی تصاویر برگ ها ساخته اند. آنها از یک مدل شبکه عمیق برانگیزاننده که با استفاده از چارچوب های Caffe اجرا شده است، استفاده کرده اند. در این مدل میتوان برگ های بیمار را در 13 گروه از برگ های سالم با دقت حدود 96 درصد تشخیص داد. چنین مدل شناختی می تواند بعنوان یک برنامه کاربردی تلفن همراه هوشمند برای کشاورزان مورد استفاده قرار گیرد تا بیماری میوه، سبزیجات یا گیاهان را براساس تصاویر برگهای گرفته شده توسط دستگاه های تلفن همراه خود شناسایی کند. همچنین این امکان را به آنها میدهد تا در کنار داده های مکمل، داروهای آفتکش یا سموم دفع آفات را انتخاب کنند.
از DL همچنین در سنجش از دور برای تشخیص و طبقه بندی زمین و گیاهان استفاده شده است. راستای تعیین شده در این آثار امکان نظارت و مدیریت خودکار اراضی کشاورزی در مقیاس های بزرگ را فراهم کرده است. در اکثر چنین کارهایی، از شبکه های پیچیده عمیق برای یادگیری تصاویر از زمین یا محصولات استفاده می شود. گزارش شده است که استفاده از CNN در تشخیص 85 درصد از محصولات مهم از جمله گندم، آفتابگردان، سویا و ذرت دقت 85 درصد داشته است، در حالی که نسبت به سایر رویکردها مانند MLP و جنگل تصادفی (RF) بهتر عمل کرده است.
علاوه بر این، گزارش شده است که DL برای کارهای پیشبینی و تشخیص در کشاورزی اتوماتیک مورد استفاده قرار می گیرد. بعنوان مثال، از مدل DL مبتنی بر CNN های عمیق برای شناسایی مانع در مزارع کشاورزی استفاده کرده است که ماشین های مستقل را قادر می سازد تا با خیال راحت در آنها کار کنند. سیستم پیشنهادی با استفاده از زمینه (مثلا محصولات ردیفی یا چمن زنی)، قادر به شناسایی یک شی استاندارد شده با دقت بین 90.8 درصد تا 90.9 درصد بود. علاوه بر این، تشخیص میوه و یافتن مرحله رسیدن (خام یا رسیده) برای برداشت خودکار بسیار مهم است. سا و همکاران برای تجزیه و تحلیل تصویر میوه ها از نوعی CNN بنام CNN مبتنی بر منطقه 27 استفاده کرد. تصویر ورودی سیستم در دو حالت ارائه میشود: یکی حاوی رنگ های RGB و دیگری نزدیک مادون قرمز. اطلاعات این تصاویر در مدل ترکیب شده و در مقایسه با مدل های آموزشی مبتنی بر پیکسل، به بهبود تشخیص رسیده است.
7) تحصیلات:
IoT و DL در بهره وری سیستم های آموزش از مهد کودک تا آموزش عالی نقش دارند. دستگاه های تلفن همراه می توانند داده های زبان آموزان را جمع آوری کرده و از روش های تحلیلی عمیق برای پیشبینی و تفسیر پیشرفت و دستاوردهای زبان آموزان استفاده کنند. فناوری واقعیت افزوده همراه با پوشیدنی ها و دستگاه های تلفن همراه نیز کاربردهای بالقوه ای برای روش های DL در این زمینه است تا دانش آموزان را با انگیزه کرده و دروس و مطالعات را جالب تر و روش های یادگیری آموزشی را کارآمد جلوه دهد. علاوه بر این، DL می تواند بعنوان یک ماژول شخصی برای توصیه مطالب مرتبط تر به مربی مورد استفاده قرار گیرد. برنامه های DL در حوزه های دیگر، مانند ترجمه زبان طبیعی و خلاصه کردن متن، هنگام یادگیری آنلاین از طریق دستگاه های تلفن همراه، برای آموزش هوشمندانه یاری خواهد کرد.
علاوه بر این، ظهور دوره های گسترده آنلاین (s28MOOC) و محبوبیت آنها در بین دانشجویان باعث شده است که دادههای زیادی از رفتار فراگیران در چنین دورههایی تولید شود. تجزیه و تحلیل Region-based می تواند به شناسایی دانش آموزان تلاشگر در جلسات ابتدایی یک دوره کمک کند و پشتیبانی و توجه کافی را از مربیان به آن دانش آموزان برای دستیابی به عملکرد بهتر ارائه دهد. یانگ و همکاران روشی را برای پیش بینی نمرات دانش آموزان در MOOC پیشنهاد دادند. آنها هنگامی که دانش آموزان در حال تماشای این فیلم و تعامل با آن هستند، از داده های clickstream جمع آوری شده از فیلم های سخنرانی استفاده میکنند. داده های Clickstream به یک سری RNN سری زمانی تغذیه می شوند که از عملکرد قبلی و داده های clickstream یاد می گیرند. علاوه بر این، پیچ و همكاران از شبكه های RNN و LSTM استفاده كردند تا بتوانند براساس فعالیت های گذشته و تعامل آنها در MOOC ، پیشبینی پاسخ های مربی به تمرین ها و آزمون ها را مدل كنند. نتایج نشان داد که روش های پیگیری دانش بیزی (29BKT) ، که از یک مدل مارکوف پنهان (30HMM) برای به روزرسانی احتمالات مفاهیم مجزا استفاده میکند، بهبود یافته است. محمود و همکاران همچنین از DNN ها برای یک چارچوب شخصی آموزش الکترونیکی و یادگیری الکترونیکی مبتنی بر فناوری های IoT ، با هدف توسعه و تحویل محتوای آموزشی در شهرهای هوشمند استفاده کردند. چارچوب پیشنهادی آنها روی زیرساخت IoT (بعنوان مثال، سنسورهای تلفن هوشمند، سنسورهای ساعت هوشمند، فناوری های واقعیت مجازی) ایجاد شده است که کاربران را به منظور بهینه سازی فرایندهای آموزش و یادگیری به یکدیگر متصل می کند. آنها از DNN برای شناسایی فعالیت های انسانی برای ارائه محتوای آموزشی تطبیقی به دانشجویان استفاده می کردند.
نظارت بر اشغال کلاس درس، برنامه دیگری است که توسط کانتی و همکاران بررسی شده است. در این کار، نویسندگان دو روش برای سرشماری و تخمین تراکم را پیشنهاد کرده اند، هر دو بر اساس معماری CNN برای شمارش دانش آموزان در یک کلاس. این الگوریتم ها بر روی سیستم عامل موبایل ARM بدون طبقه بندی مستقر شده اند. الگوریتم های آنها از تصاویر گرفته شده با دوربین هایی از سه کلاس درسی که در هر 10 دقیقه 3 عدد عکس می گیرند، دریافت شده است. آنها گزارش می دهند که خطای میانگین-مربع (RMS) الگوریتم های آنها حداکثر 8.55 است.
8) صنعت:
برای بخش صنعت، IoT و سیستم های فیزیکی-سایبری (CPS) عناصر اصلی برای پیشبرد فناوری های تولید به سمت تولید هوشمند هستند (پیشتر، صنعت 0.4). تهیه سیستم های هوشمند با دقت بالا در چنین کاربردهایی بسیار مهم است، زیرا مستقیما منجر به افزایش کارایی و بهره وری در خطوط مونتاژ/محصول و همچنین کاهش هزینه های نگهداری و هزینه های بهره برداری می شود. بنابراین، DL می تواند در این زمینه نقش اساسی داشته باشد. درواقع، طیف گسترده ای از برنامه های کاربردی در صنعت (مانند بررسی بصری خطوط محصول، تشخیص و ردیابی اشیا، کنترل رباتها، تشخیص اشتباه و…) می توانند از معرفی مدل های DL بهرمند شوند. بازرسی بصری با استفاده از معماری های CNN از جمله AlexNet و GoogLeNet بر روی سیستم عامل های مختلف (Caffe, Tensorflow, and Torch) بررسی می شود. در این کار چندین تصویر از وسایل نقلیه تولید شده در خط مونتاژ بهمراه حاشیه نویسی آنها به سیستم DL ارسال می شود. علاوه بر این، Tensorflow از نظر زمان آموزش سریعترین چارچوب بود، جایی که این مدل در مدت زمان کوتاه تر به اوج دقت خود رسید و پس از آن Torch و سپس Caffe قرار گرفت.
شائو و همکاران از DNN ها برای استخراج ویژگی ها در تشخیص اشتباه (همچنین بعنوان سیستم تشخیص و تقسیم اشتباهات (FDC)) برای دستگاه های چرخان استفاده می کنند. مدل هایی با استفاده از رمزگذار خودکار بیصدا (DAE) و رمزگذار خودکار قراردادی (CAE) توسعه داده شدند. ویژگی های آموخته شده از این مدل ها هر دو با استفاده از روشی به نام پیشبینی حفظ محل (LPP) تصفیه شده و برای تشخیص اشتباه به یک طبقه بند نرم کننده (softmax) تغذیه شدند. ورودی سیستم، داده های لرزشی دستگاه گردان است. در سیستم آنها هفت شرط عملیاتی درنظر گرفته شده است که شامل کارکرد نرمال، اشتباه لغزشی، چهار رده اشتباه دیگر و اشتباهات دارای عدم تعادل است. باتوجه به داده های لرزشی، سیستم تشخیص دهنده می فهمد که دستگاه در حالت عادی است یا در یکی از شرایط اشتباه. با توجه به آزمایشات آنها برای تشخیص اشتباه دستگاه های تحمل رتور و لوکوموتیو، رویکرد پیشنهادی گزارش شده است تا از روشهای یادگیری کم عمق CNN بهتر باشد.
در مطالعه دیگری که توسط لی گزارش شده است، یک مدل DBN در رابطه با استقرار IoT و بستر ابری برای پشتیبانی از تشخیص اشتباهات انواع نقوص در ماژول چراغ های جلوی اتومبیل در یک تولید کننده وسیله نقلیه پیشنهاد گردیده است. نتایج آنها عملکرد برتر مدل DBN را بیش از دو روش پایه با استفاده از SVM و عملکرد پایه شعاعی (RBF)، از نظر میزان خطا در مجموعه داده های آزمایشی، تأیید کرد. با اینحال، میزان خطای گزارش شده برای مجموعه داده های آموزشی آنها در مدل DBN قابل مقایسه با مدل SVM است. سیستم آنها برای تشخیص اشتباه در نمونه های ویفری یک فرآیند فوتولیتوگرافی استفاده شده است. نتایج نشان میدهد که SdA منجر به 14 درصد دقت بیشتر در شرایط پر سر و صدا در مقایسه با چندین روش پایه از جمله K-نزدیکترین-همسایگان 32 و SVM میشود. یان و همکاران نیز از دستگاه SdA همراه با دستگاه های یادگیری فوری برای تشخیص ناهنجاری در رفتار سیستم احتراق توربین گازی بهره جستند. براساس نتایج آنها، استفاده از ویژگی های آموخته شده توسط SdA منجر به طبقه بندی دقیقتر در مقایسه با استفاده از ویژگی های دستکاری شده در سیستم آنها می شود.
9) دولت:
دولت ها می توانند از راه اتصال پیشرفته و هوشمندانه ناشی از همگرایی IoT و DL ، مزایای بالقوه بزرگی را بدست آورند. درواقع طیف گسترده ای از وظایف مربوط به دولت ها یا مقامات شهری نیاز به تحلیل و پیشبینی دقیق دارند. بعنوان مثال، شناخت و پیشبینی سوانح طبیعی (زمین لغزش، طوفان، آتش سوزی جنگلها و…) و نظارت بر محیط زیست از اهمیت بالایی نزد دولت ها برخوردار است تا آنها بتوانند اقدامات مناسب را انجام دهند. تصاویر سنجش از راه دور نوری که به یک شبکه عمیق از AE ها منتقل می شوند و طبقه بندی کننده های softmax توسط لیو و همکاران برای پیشبینی زمین لغزش در علم زمین شناسی ارائه شده اند. دقت 97.4 درصدی برای روش پیشنهادی گزارش شده است، بنابراین بهتر از مدل های SVM و ANN است. در یک پژوهش دیگر، از شبکه LSTM برای پیشبینی زلزله استفاده میشود. آنها از سابقه داده های وبسایت سازمان زمین شناسی ایالات متحده 33 برای آموزش استفاده کردند. سیستم آنها با داده های ورودی 1 – D و 2 – D ، به ترتیب میزان 63 و 74 درصد را کسب کرد.
در مطالعه دیگری توسط لیو و همکاران، برای تشخیص حوادث شدید آب و هوایی مانند سیکلون های گرمسیری، رودخانه های ج وی و جبهه های هواشناسی، از یک معماری CNN استفاده میشود. داده های آموزشی در سیستم خود شامل الگوهای تصویری از وقایع آب و هوایی بودند. نویسندگان سیستم خود را در چارچوب نئونی توسعه داده و با دقت 89 – ٪ 99 ٪ بدست آوردند. علاوه بر این، تشخیص خسارت در زیرساخت های شهرها ازجمله جادهها، خطوط لوله کشی انتقال آب و… مبحث دیگری است که IoT و DL می توانند در آنها منافعی را برای دولتها به ارمغان بیاورند.
مشکل تشخیص خسارت در جاده ها با استفاده از DNN هایی که داده های آن را از راه سنجش تراکم جمعیت بدست میاورند (که توسط دستگاه های IoT امکان پذیر است)، مورد بررسی قرار گرفت. شهروندان می توانند آسیب را بوسیله یک برنامه تلفن همراه به یک پلتفرم خاص گزارش دهند. با اینحال، این شهروندان دانش خاصی برای ارزیابی دقیق وضعیت خسارت جاده ای ندارند و این می تواند منجر به ارزیابی های نامشخص و یا اشتباه شود. برای از بین بردن این موارد، برنامه می تواند با تحلیل تصویر صحنه وضعیت آسیب جاده را تعیین کند. این تجزیه و تحلیل بوسیله یک CNN عمیق انجام میشود که توسط گزارش های شهروندان و همچنین نتایج بازرسی مدیر راه آموزش دیده است. از آنجا که مرحله آموزش از دایره قابلیت های تلفن های همراه خارج نیست، مدل DL روی سرور ایجاد شده و همه روزه آموزش می یابد. سپس یک برنامه Android بعد از هربار آموزش می تواند آخرین مدل را از سرور بارگیری کرده و وضعیت خسارتهای جاده ای را که توسط تصاویر گزارش شده است، شناسایی کند. ارزیابي ها در 1 ثانیه تحلیل در دستگاههای تلفن همراه، دقت طبقه بندي آسیب را 81.4 درصد نشان داد.
